3.PDF書類のテンプレートを作成
ジーニアルAI for Webでは、「OCR実行前にどのような前処理を行うか」「証憑におけるどの範囲に存在する項目を読み取るか」といった設定をOCRで使用することで、OCRの精度を高めたり、OCR結果を証憑突合時に使用しやすくしたりすることができます。
これらのOCR実行時に使用する設定のことを、ジーニアルAI for Webでは「テンプレート」と呼んでいます。
テンプレート作成方法を以下の順序で説明します。
1.標準PDFをアップロードする
ジーニアルAI for WebはOCR実行時に、ページ上の項目をテンプレートに基づき読み取る仕組みとなっています。
OCR実行時に読み取る座標や、表の設定の基準として使用するPDFページのことを、ジーニアルAI for Webでは「標準PDF」と呼びます。
また、OCR対象の証憑と各テンプレートの標準PDFの見た目の類似度によって、OCR実行時にどのテンプレートを使用するかを自動的に判断します。
1.サイドメニューの[テンプレート] をクリックし、テンプレート一覧画面を呼び出します。
2.[新規テンプレート] ボタンをクリックし、テンプレート編集画面に移動します。
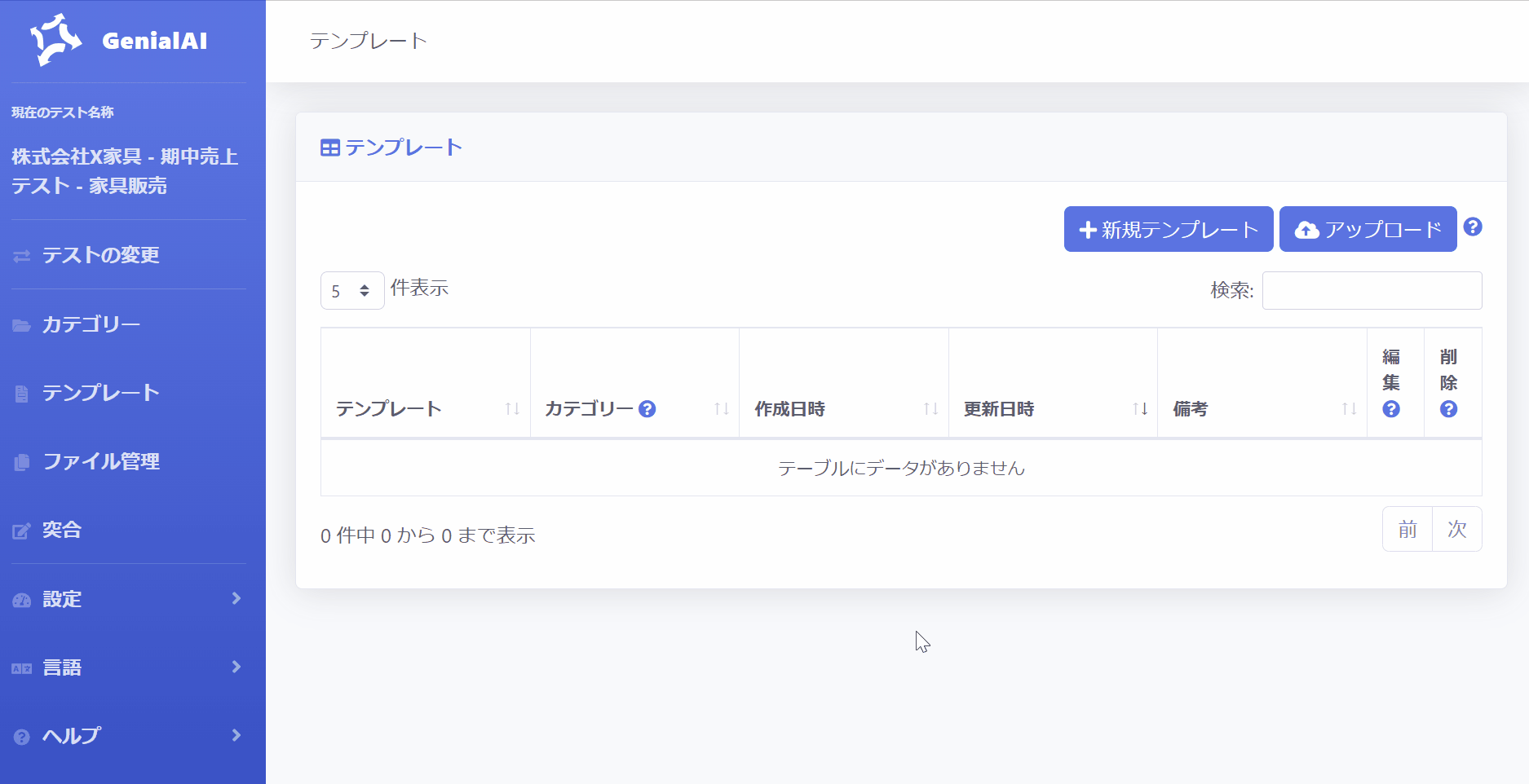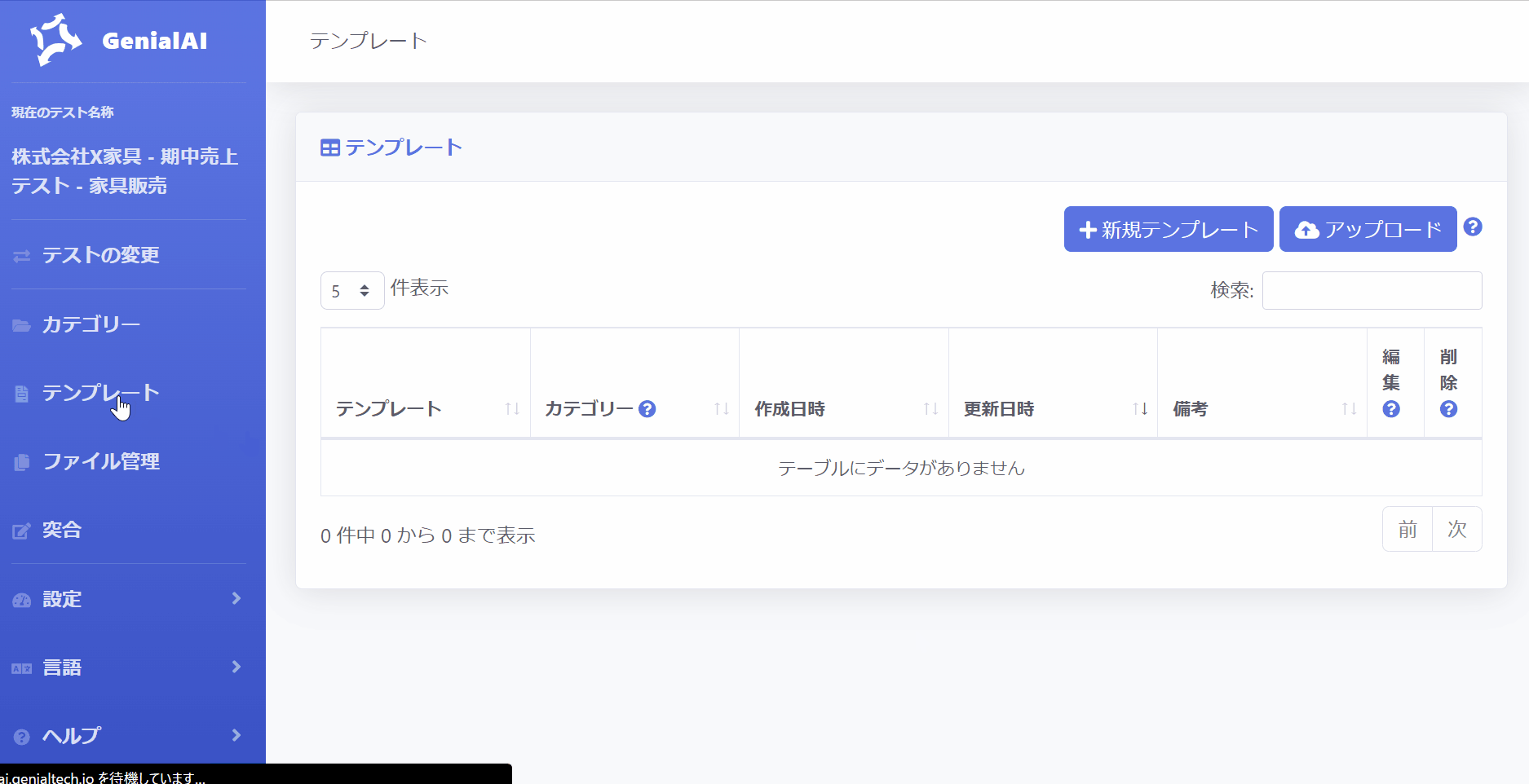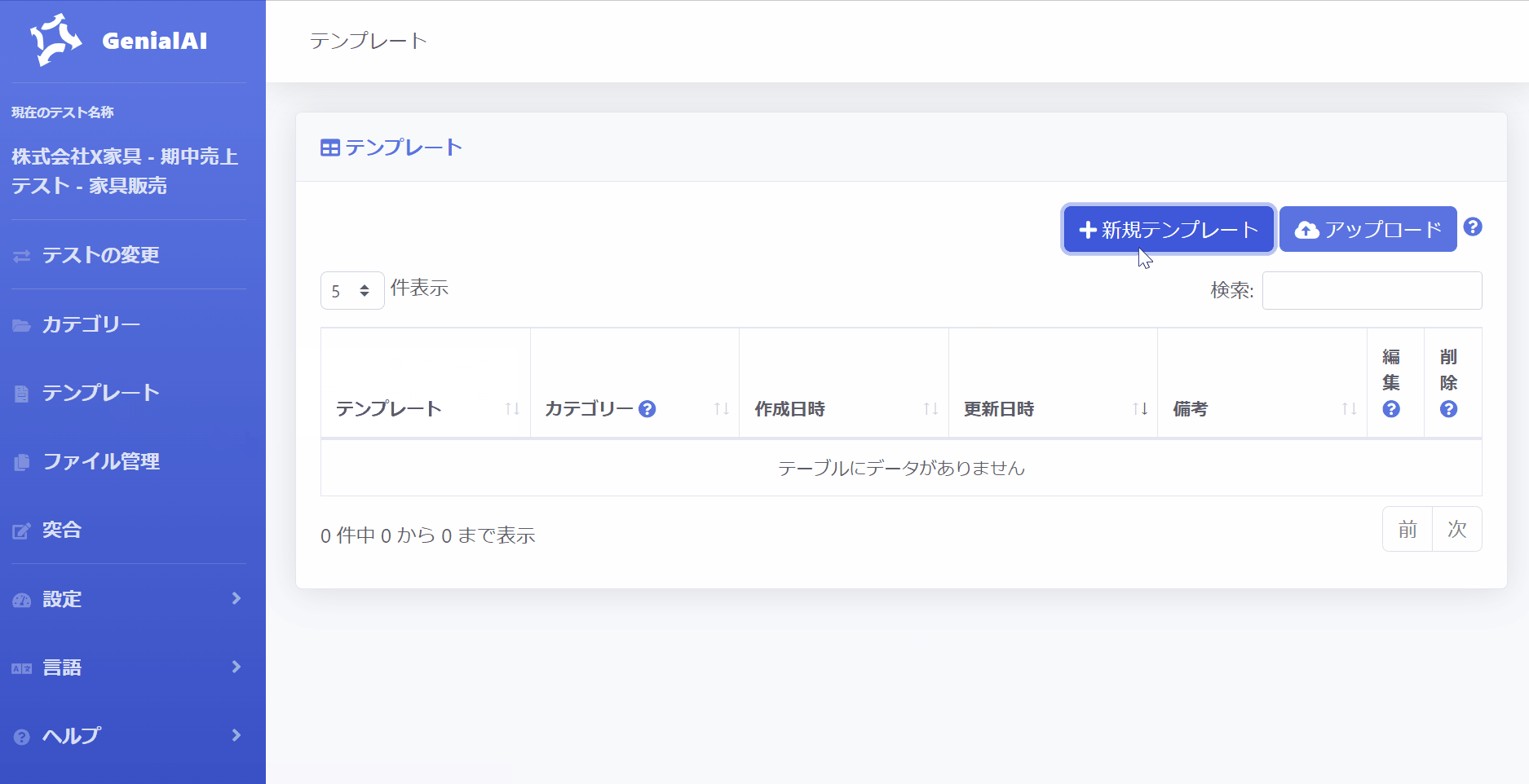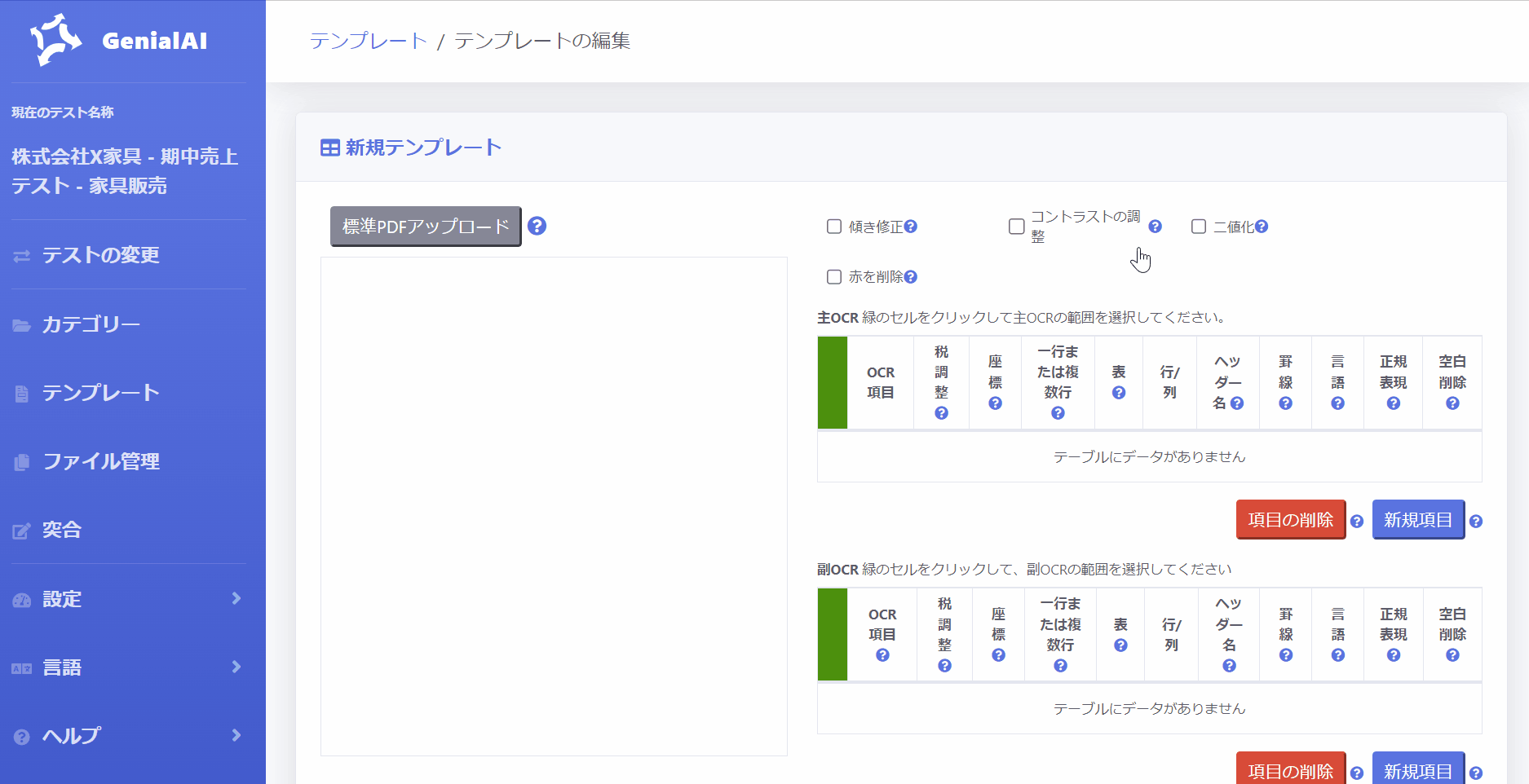
3.[標準PDFをアップロード]ボタンをクリックし、PDFファイルとページ番号を選択します。
デフォルトでテンプレート自動生成機能にチェックマークが入っています。
こちらを入れたままアップロードすると、PDFページにもとづいてOCR項目が自動生成されます。
※自動生成を使わない場合はチェックマークを外してください。
※自動生成はβ版機能ですので、十分な精度を得られないケースがあります。
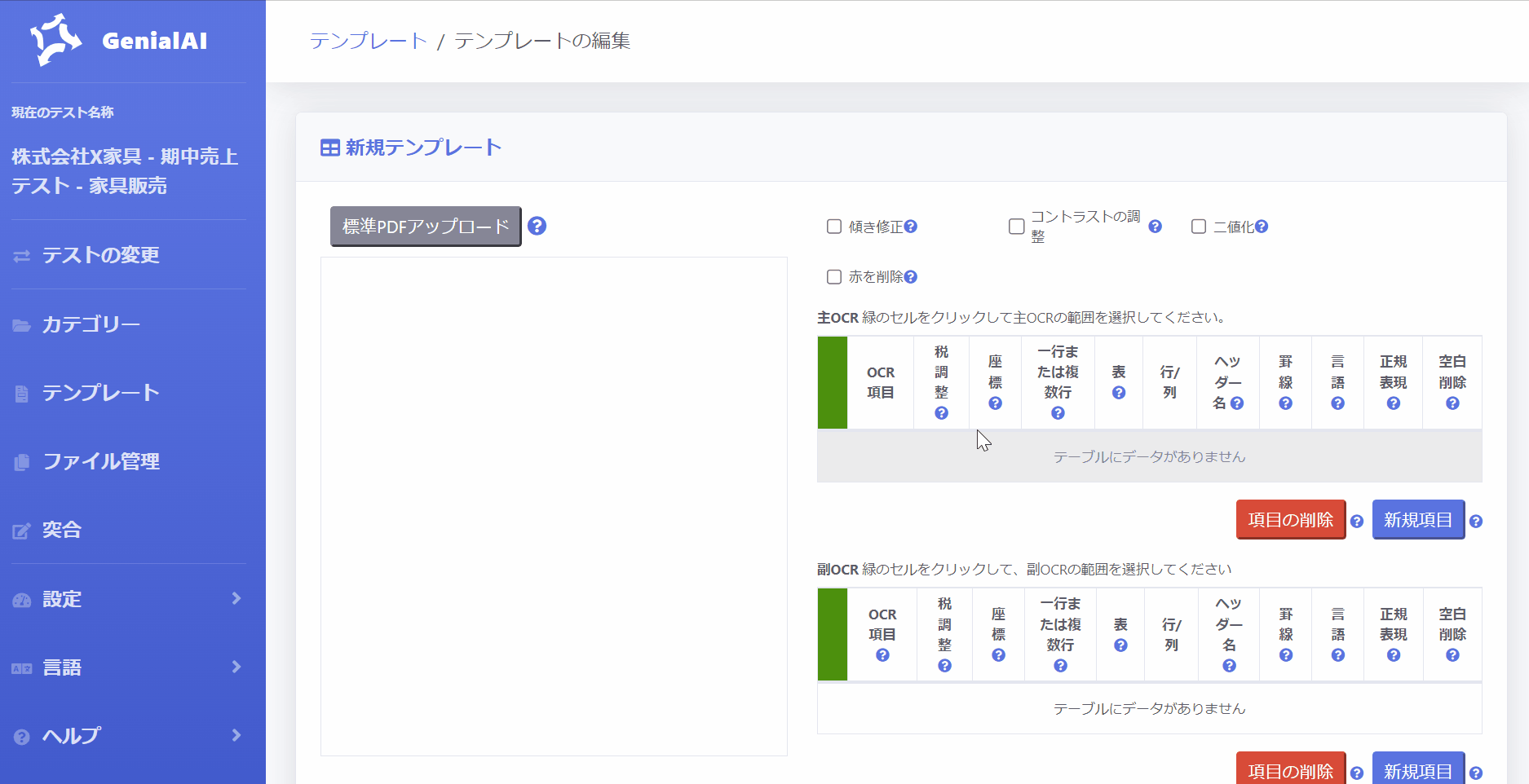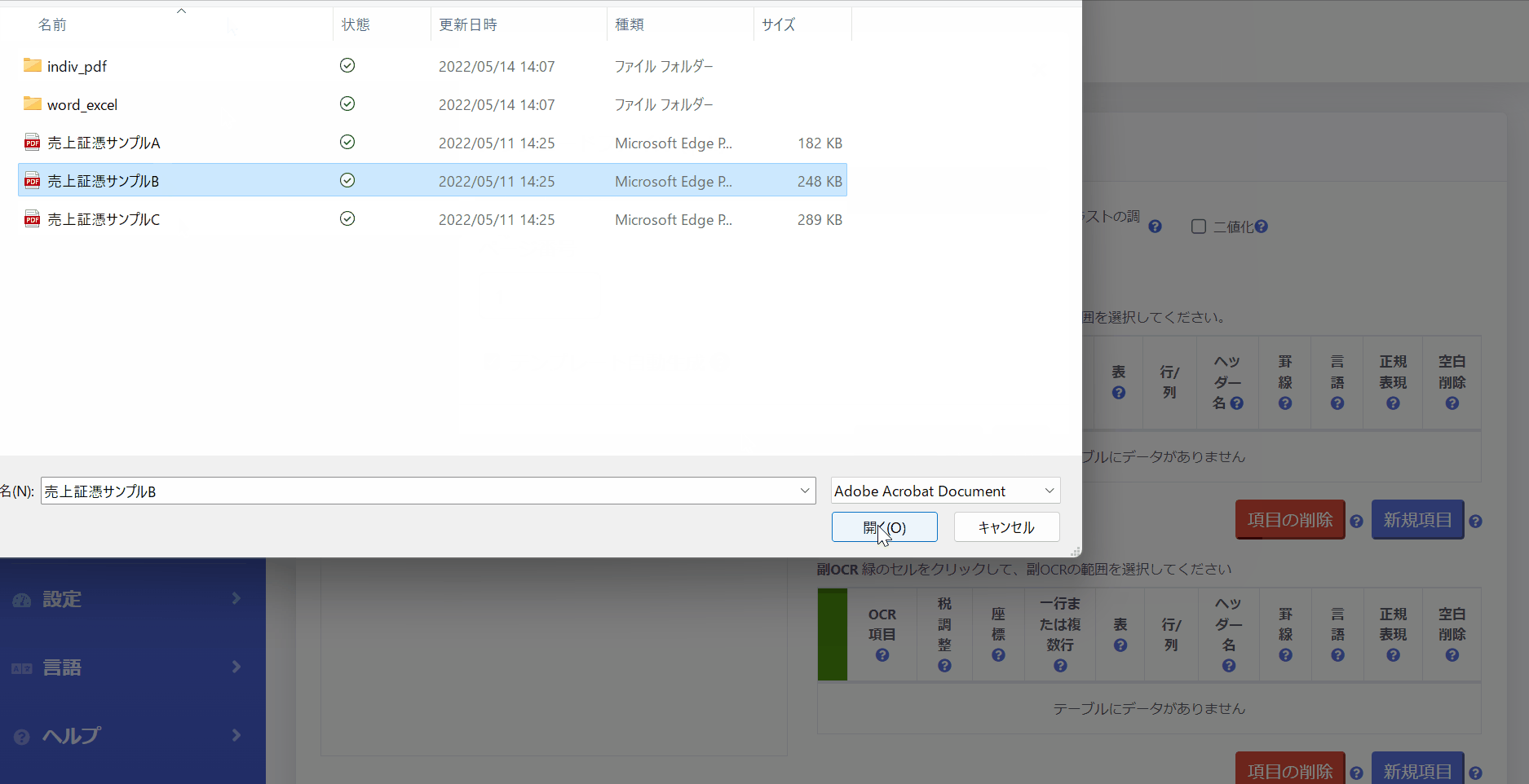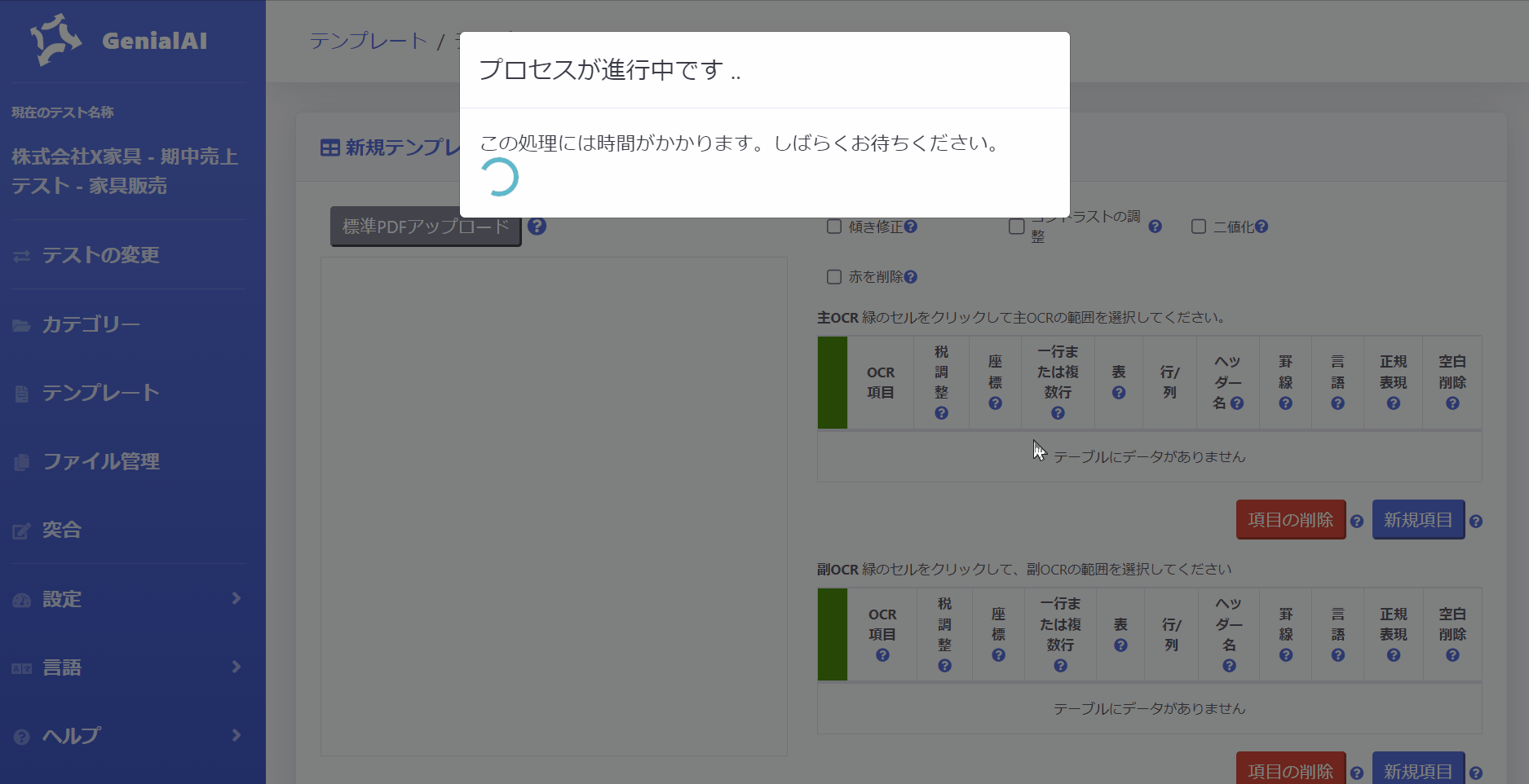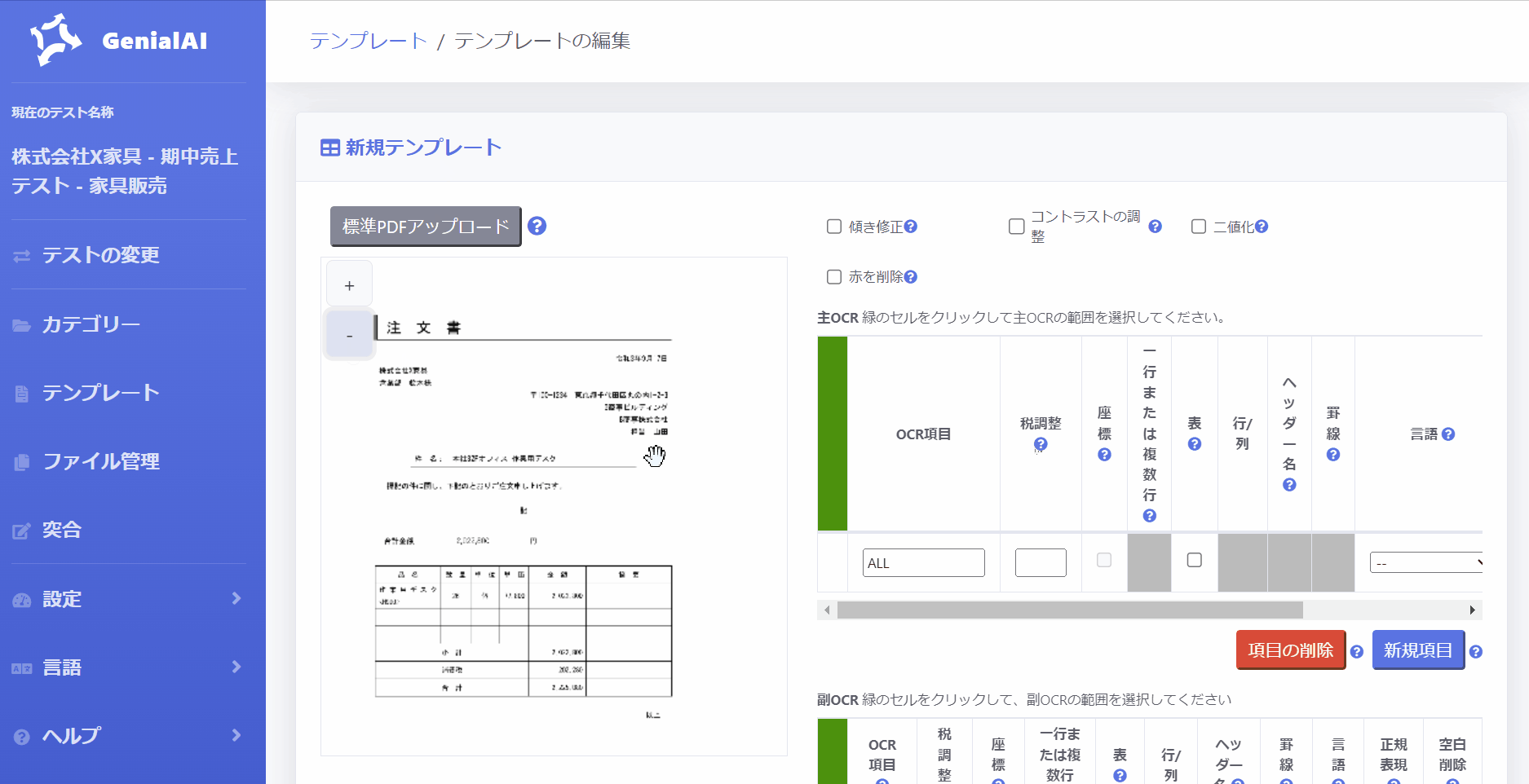
4.標準PDFをアップロードすると、画面の左側 にアップロードしたPDFページの画像が表示されます。
[+] ボタン / [–] ボタンをクリックすることで、PDFページの画像を拡大/縮小することができます。
※パスワード等によって保護されたPDFファイルは正常にアップロードできません。また、フォントが埋め込まれていないPDFファイルはアップロード後に文字化けが発生することがあります。
以下の手順で、保護が解除されてフォントが画像化されたPDFファイルを作成してください。
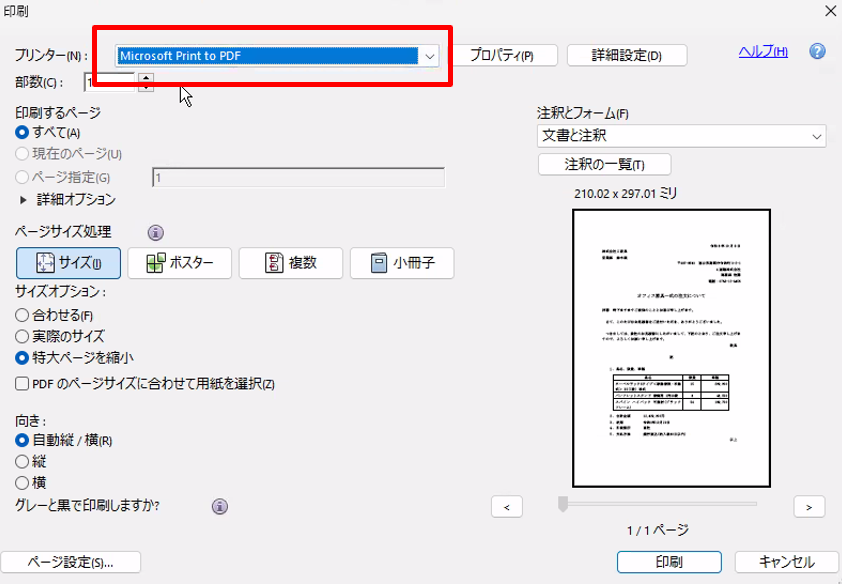
- Adobe Acrobatを開く
- Acrobatの[ファイル]の[印刷]をクリック
※PDFを新しいPDFファイルに印刷します。 - ドロップダウンメニューから[Microsoft Print to PDF]または[Adobe PDF]を選択し[印刷]をクリック
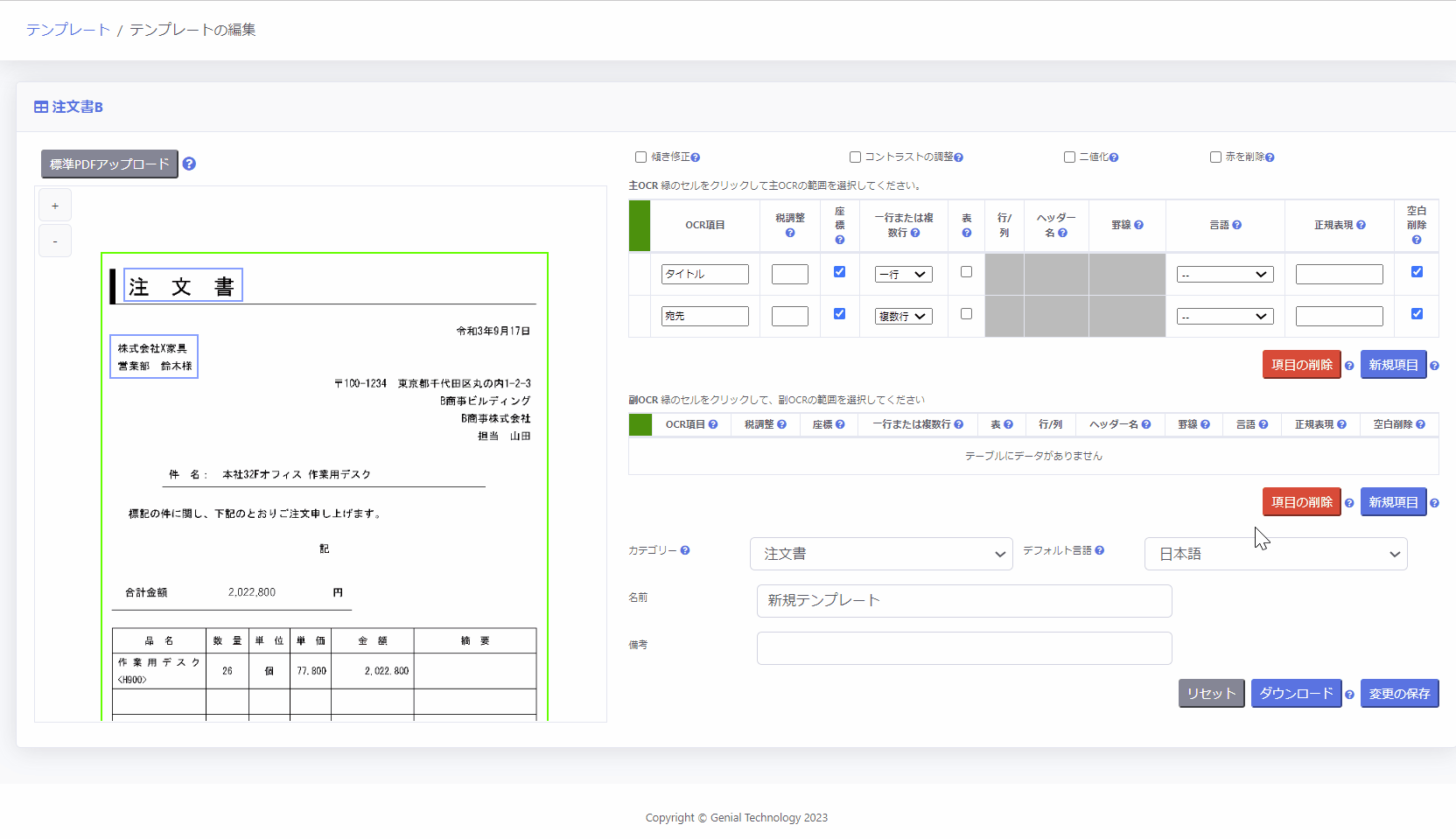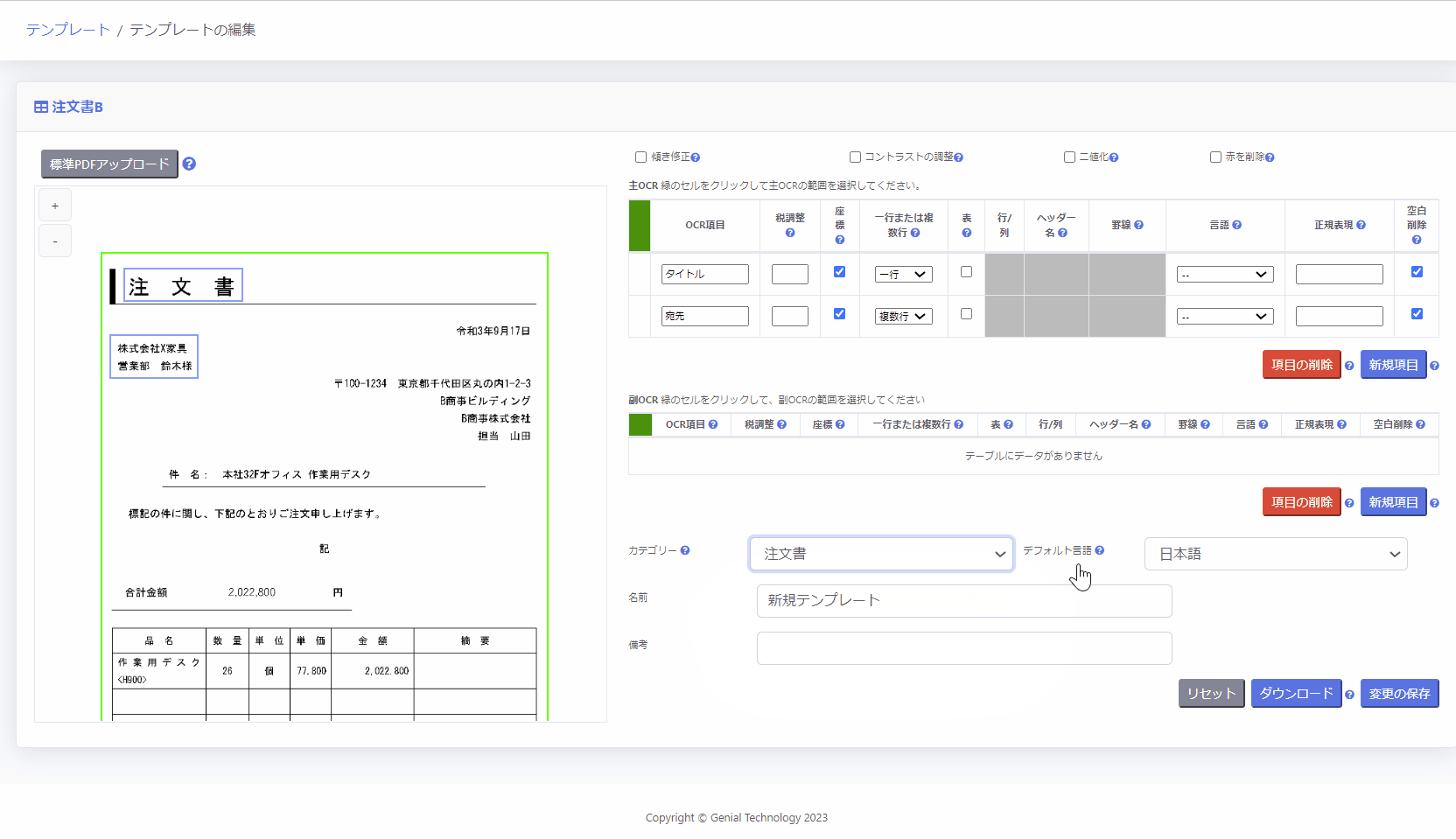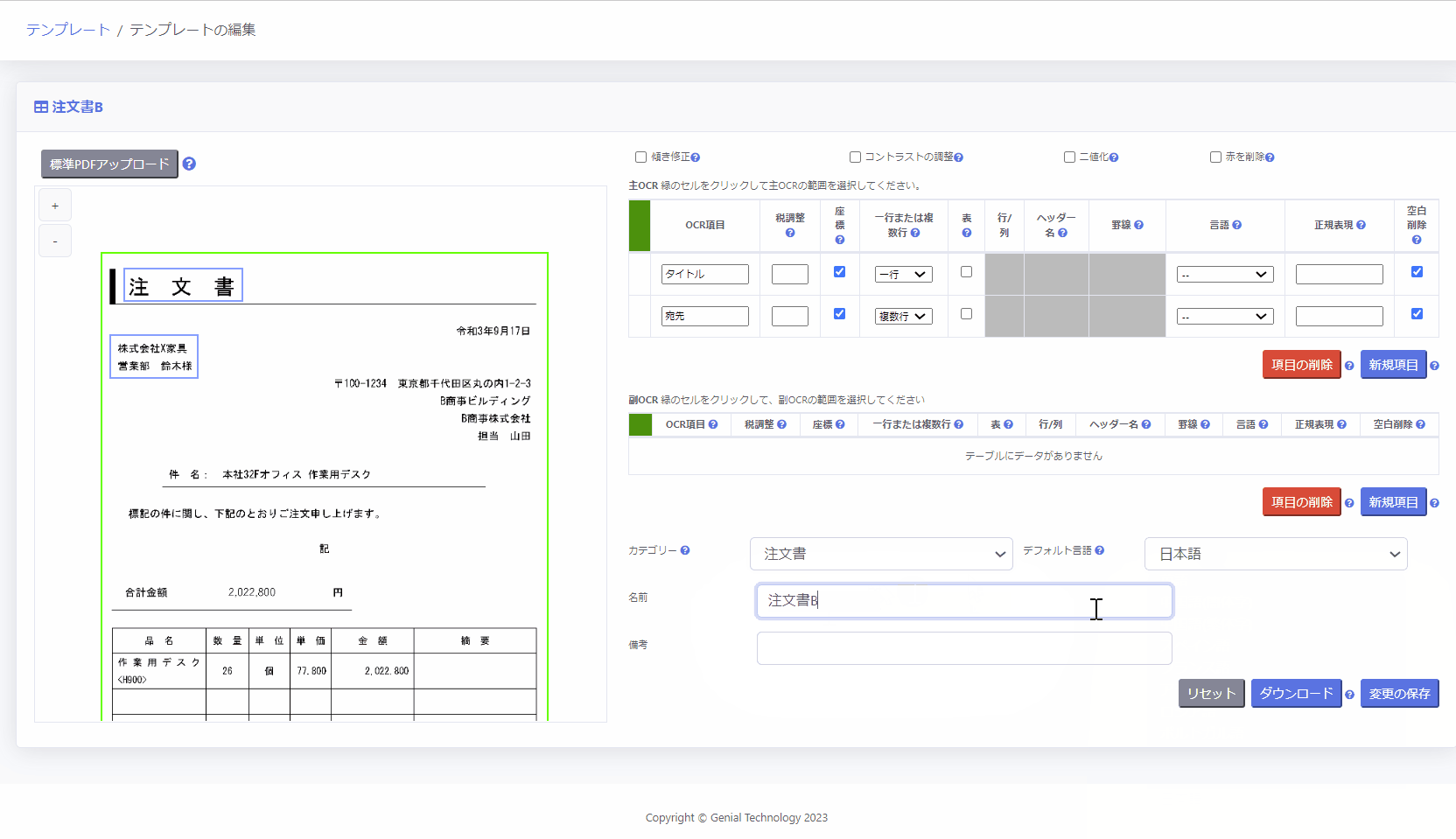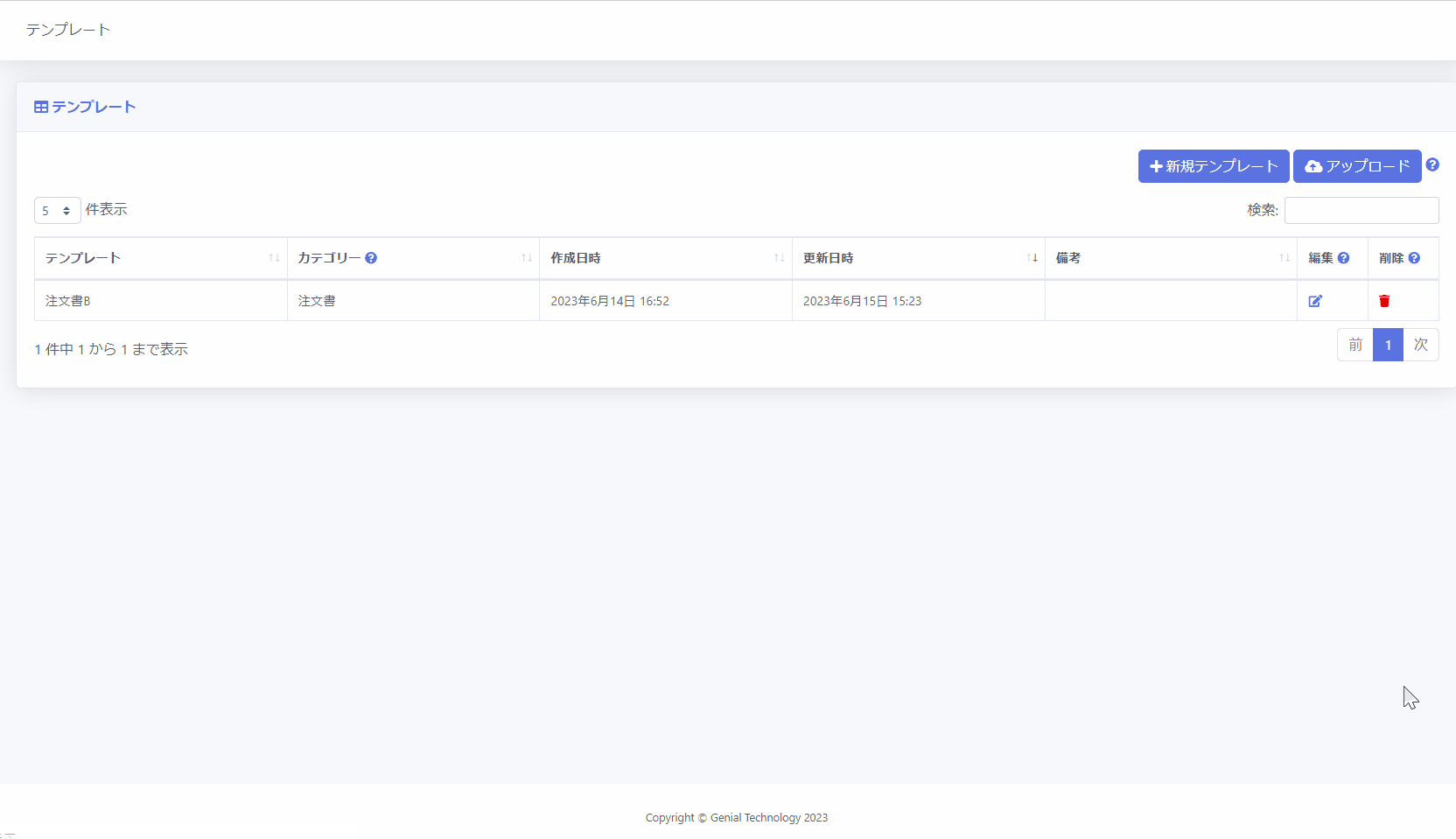
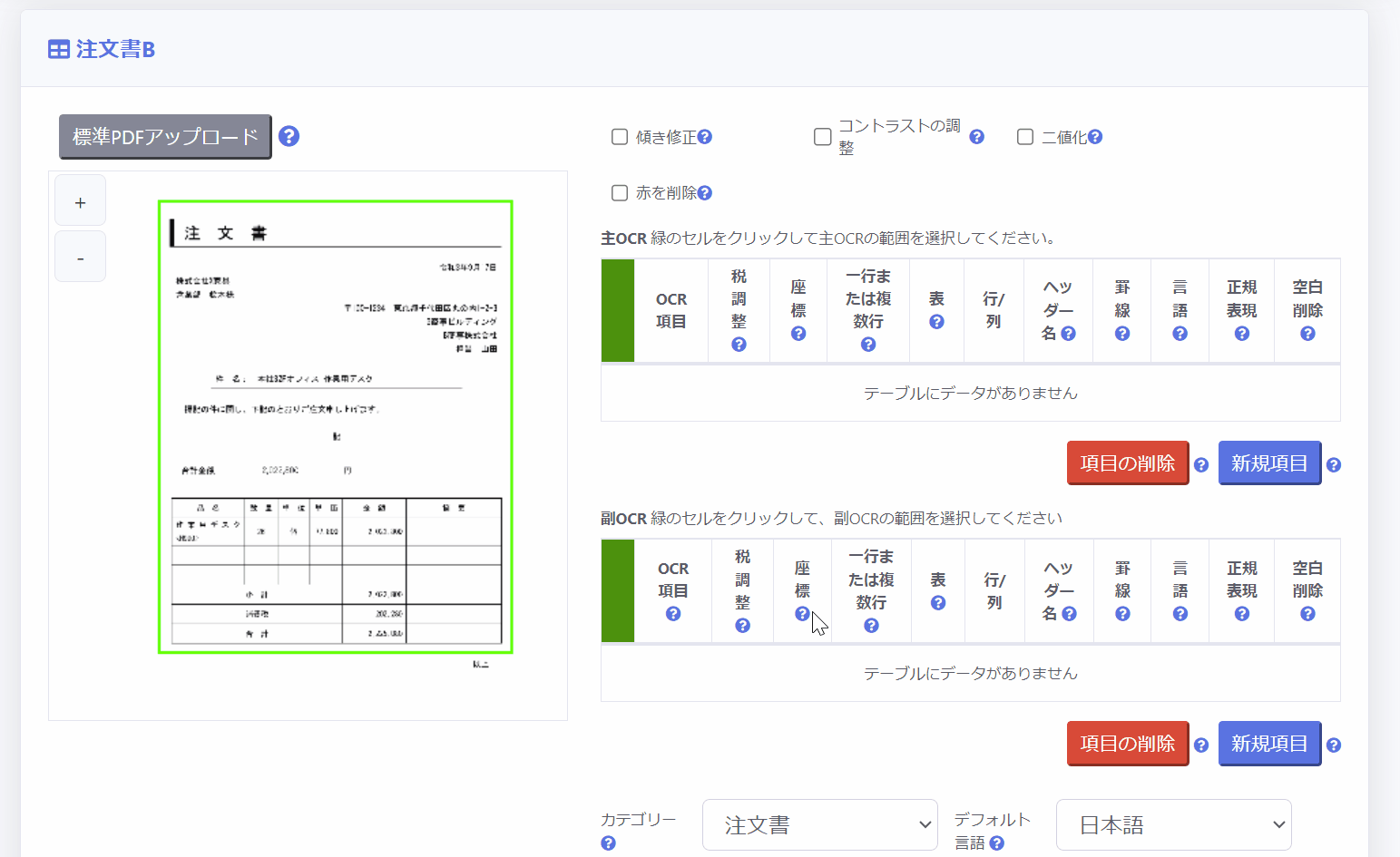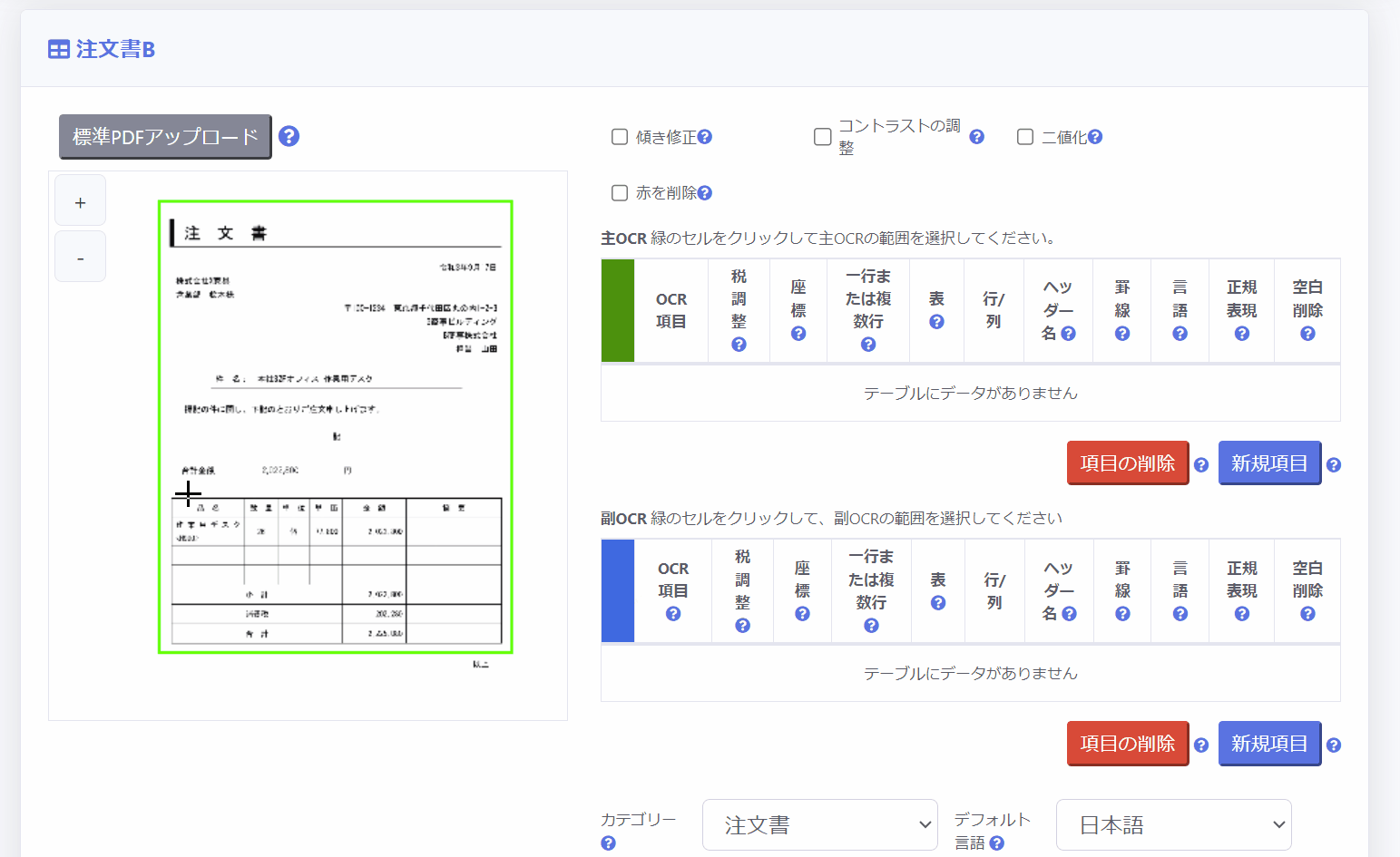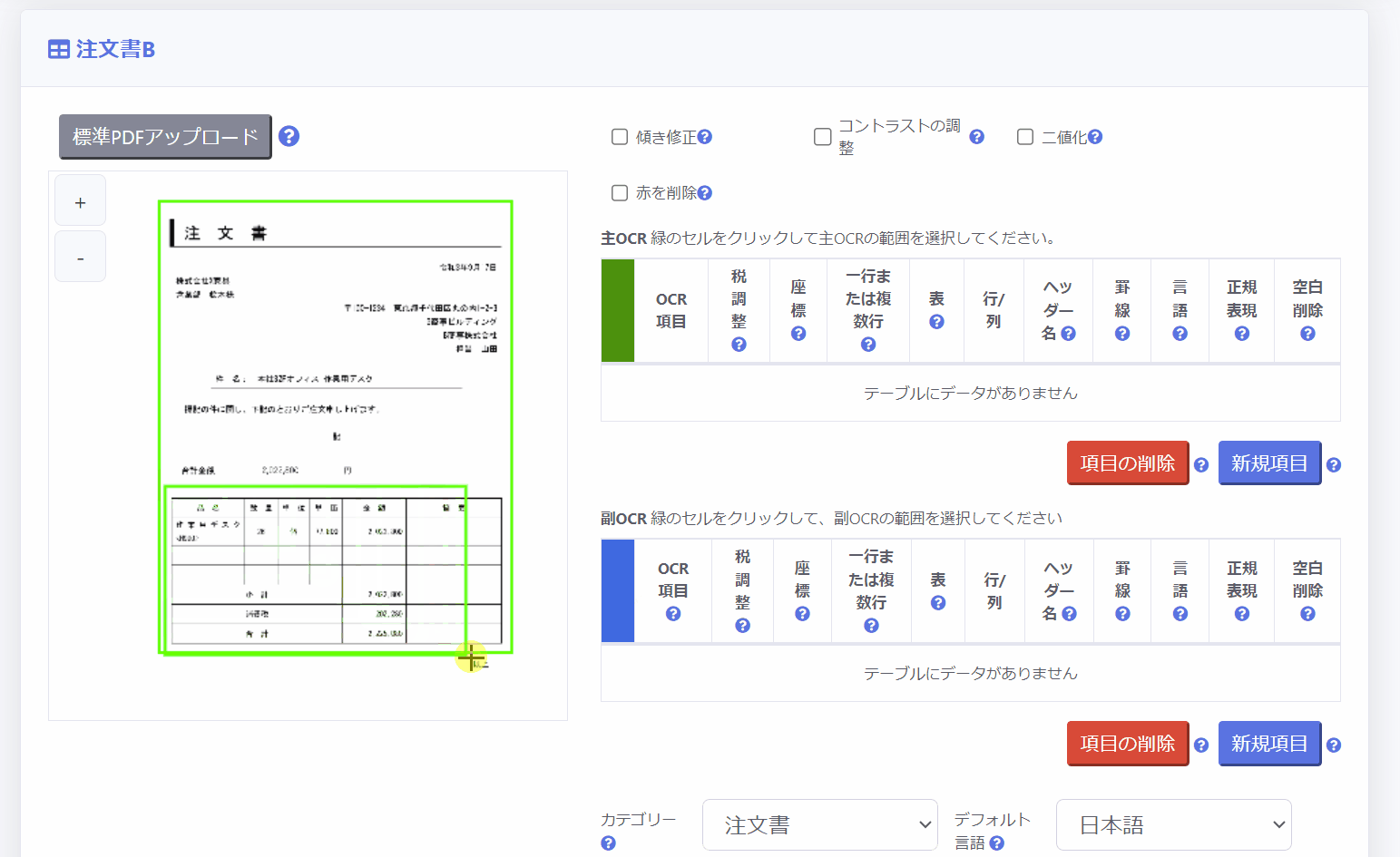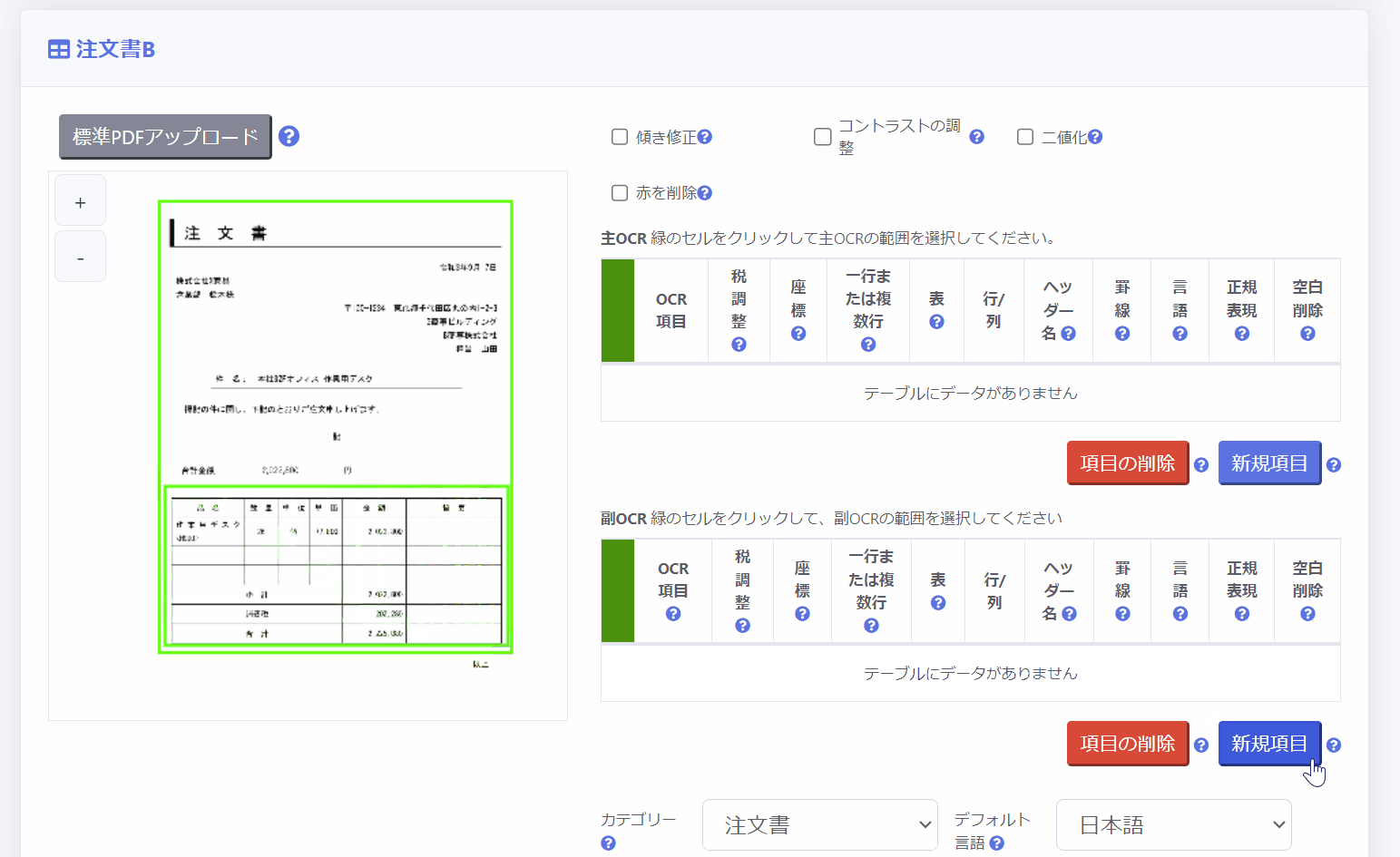
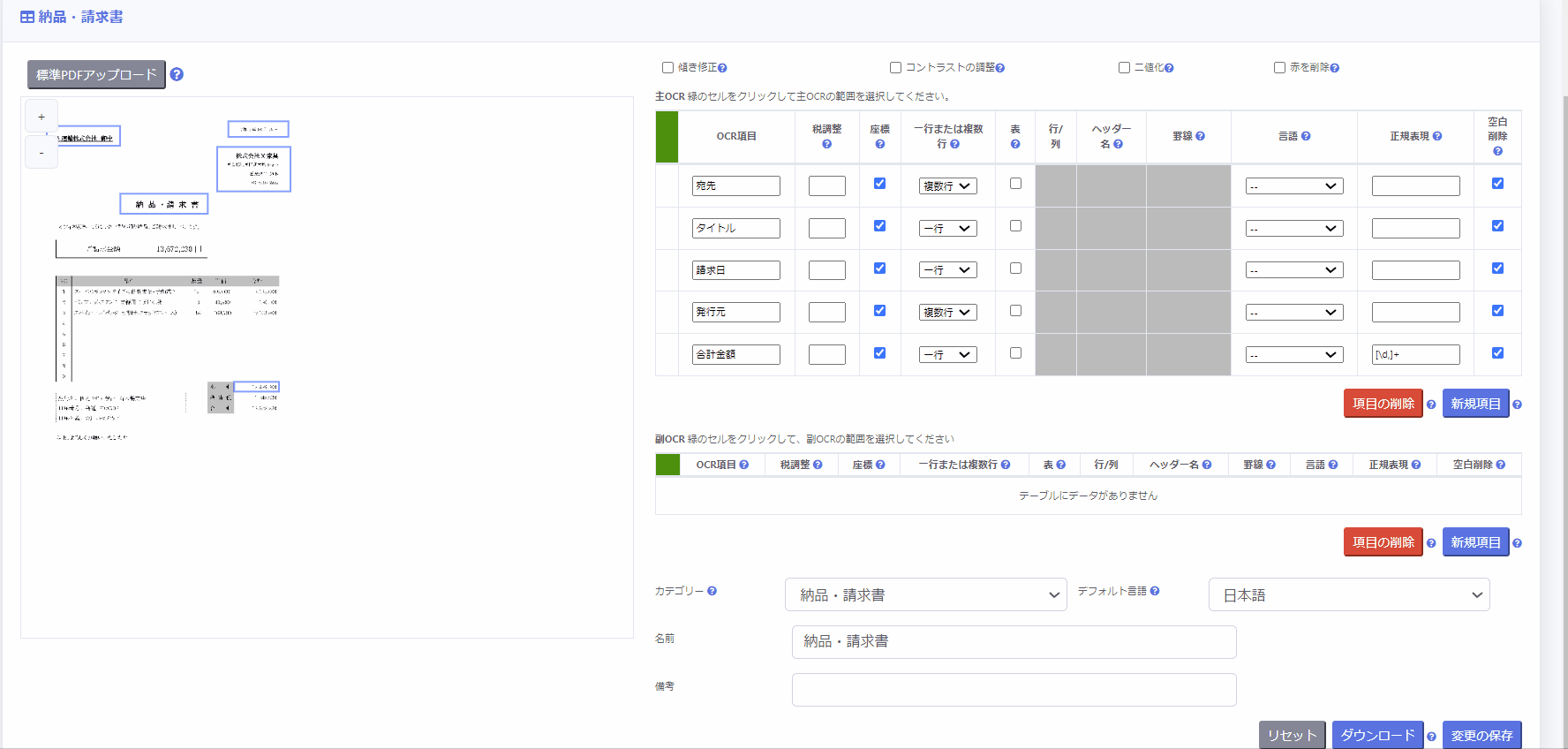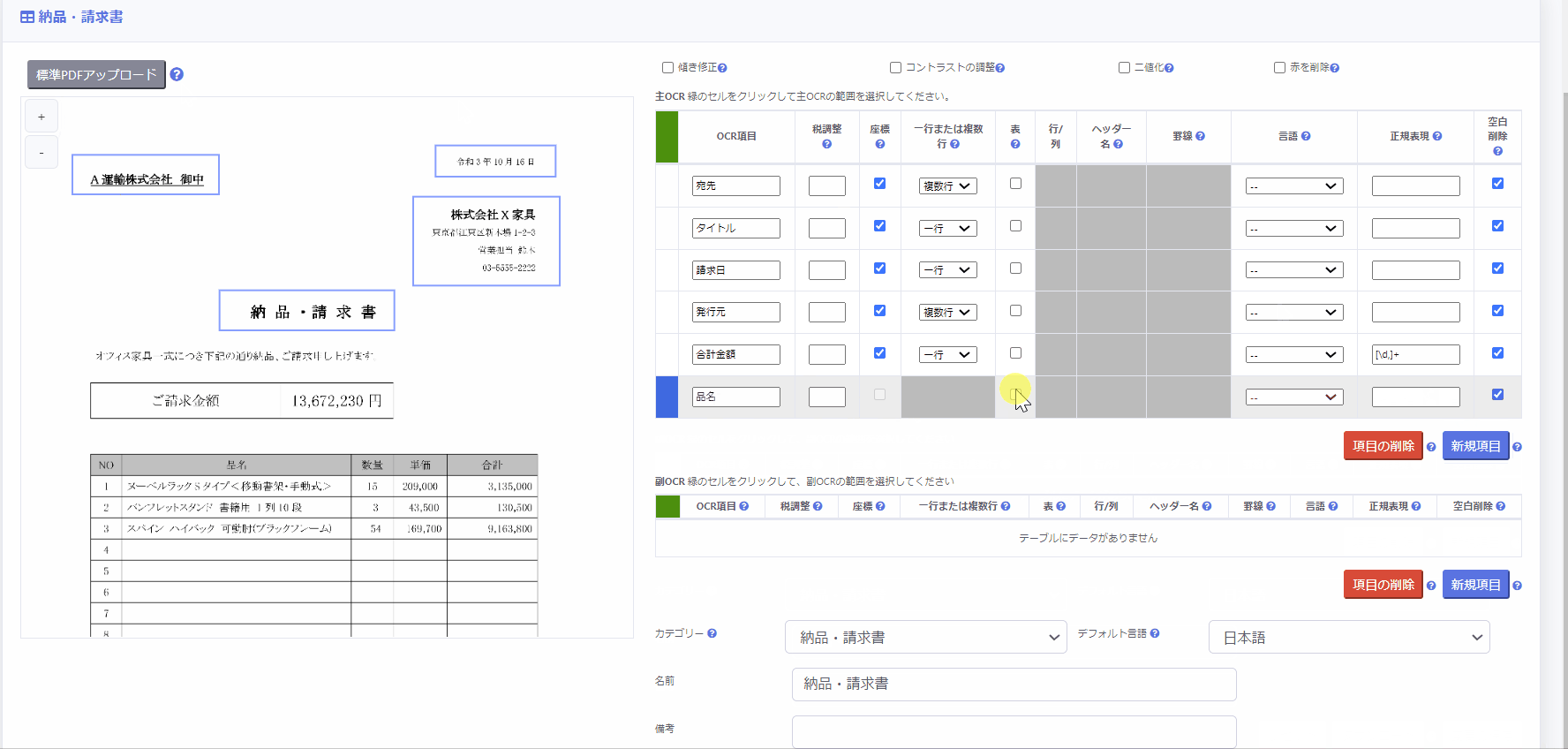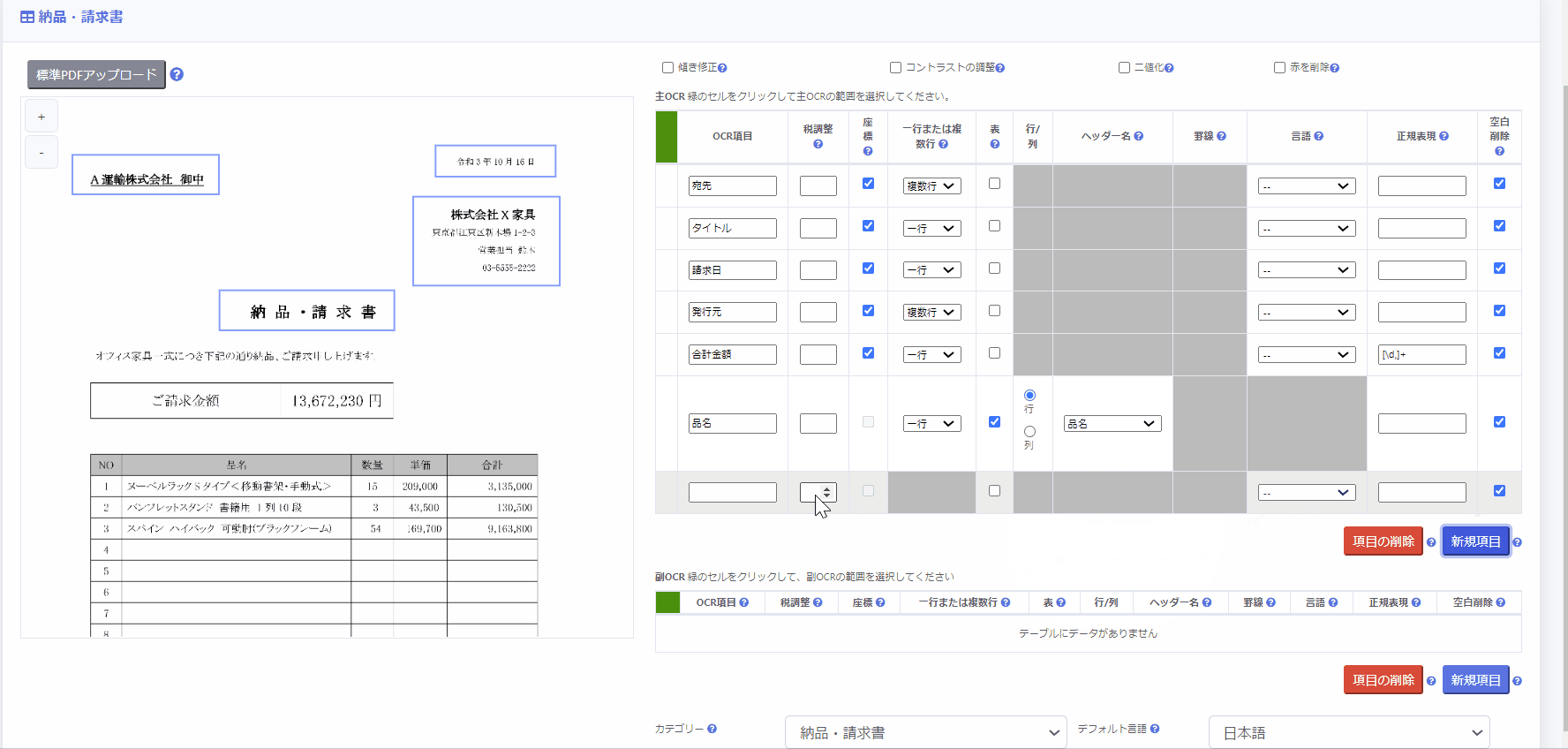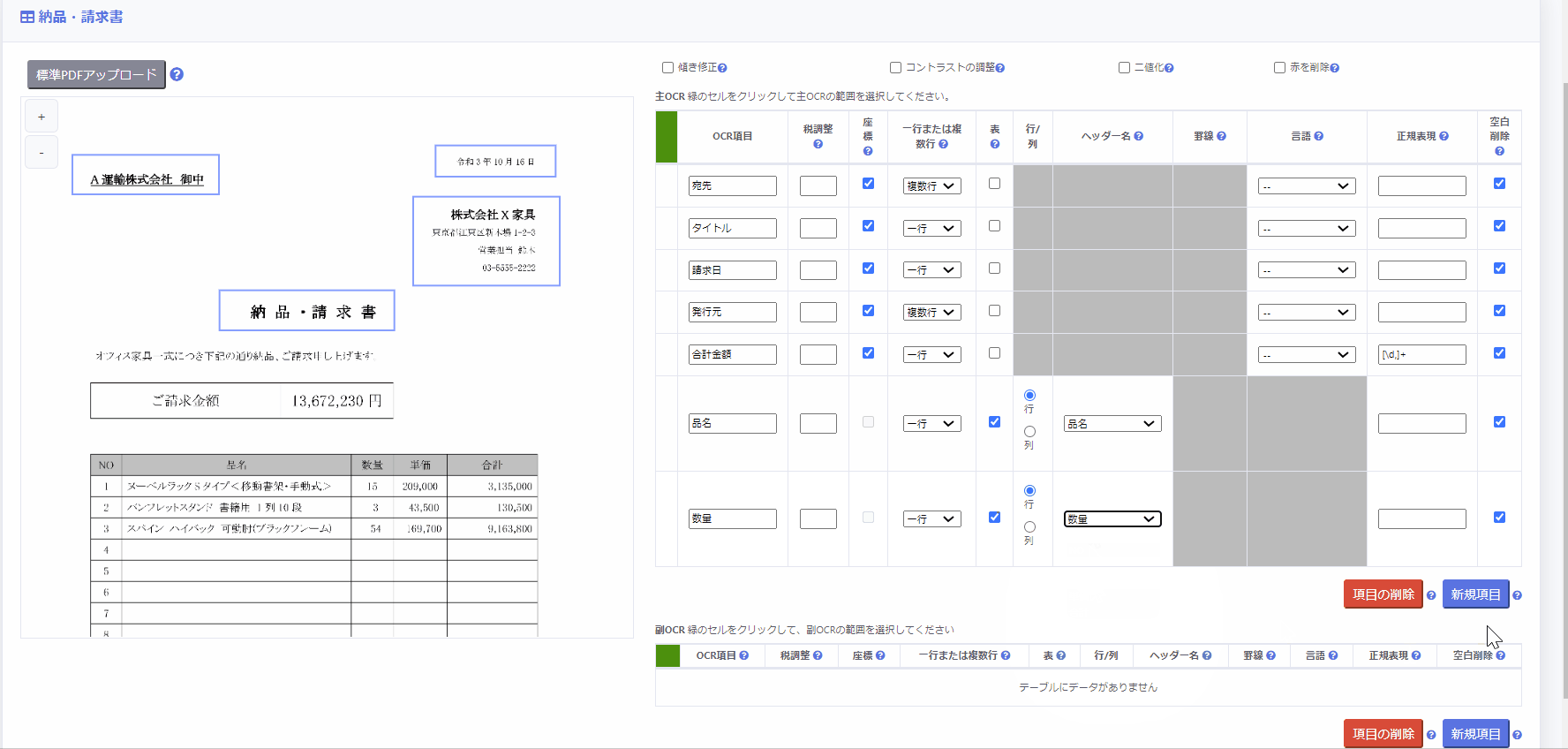
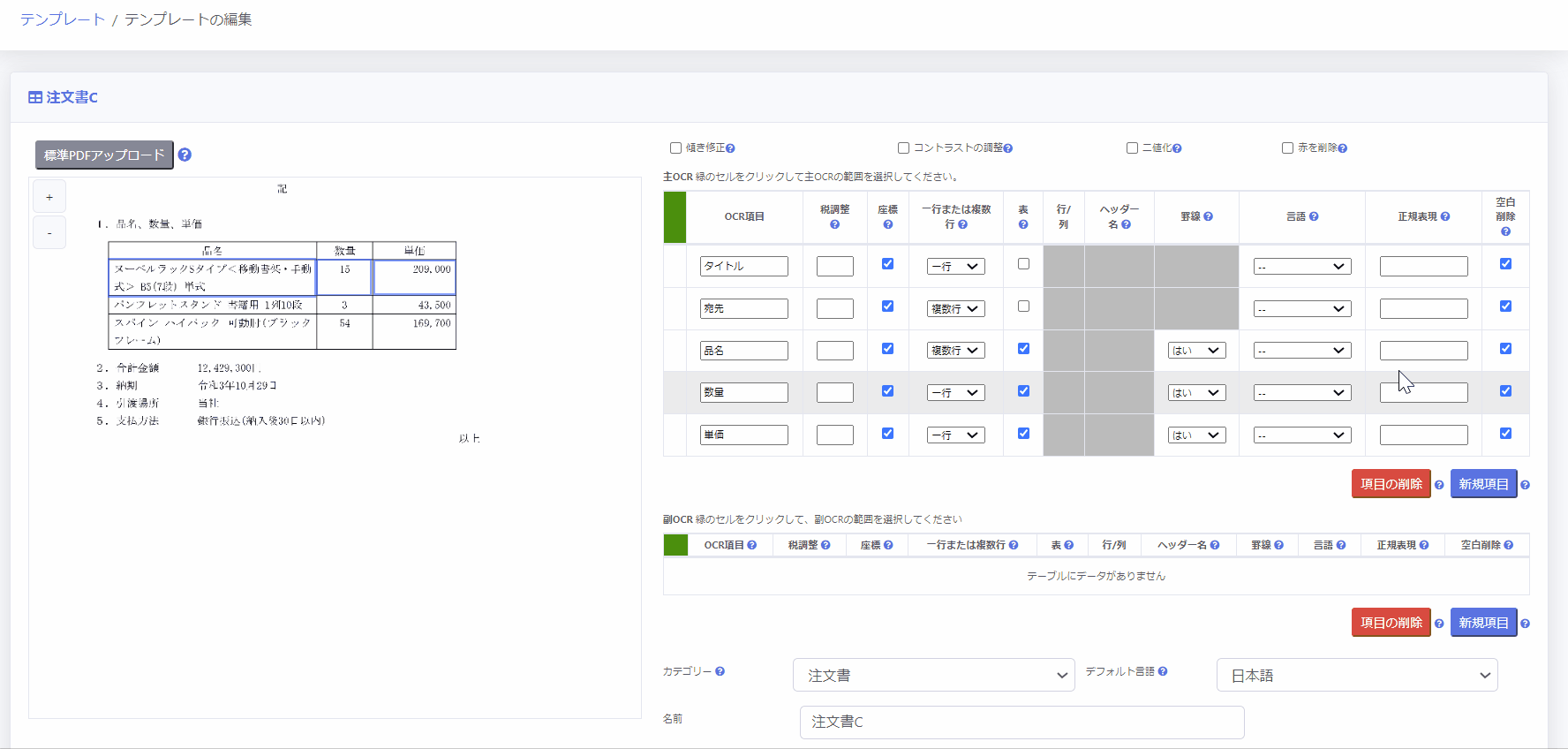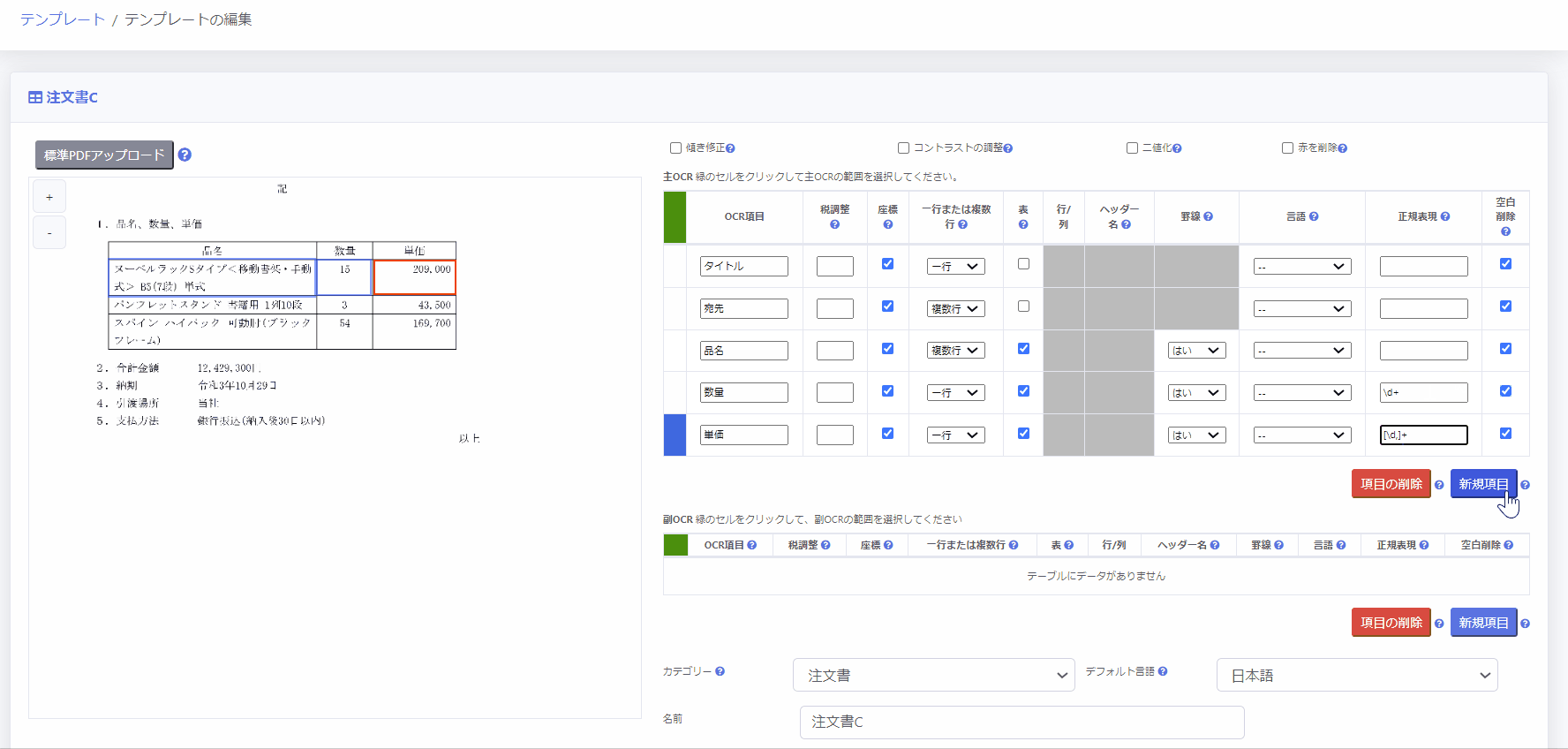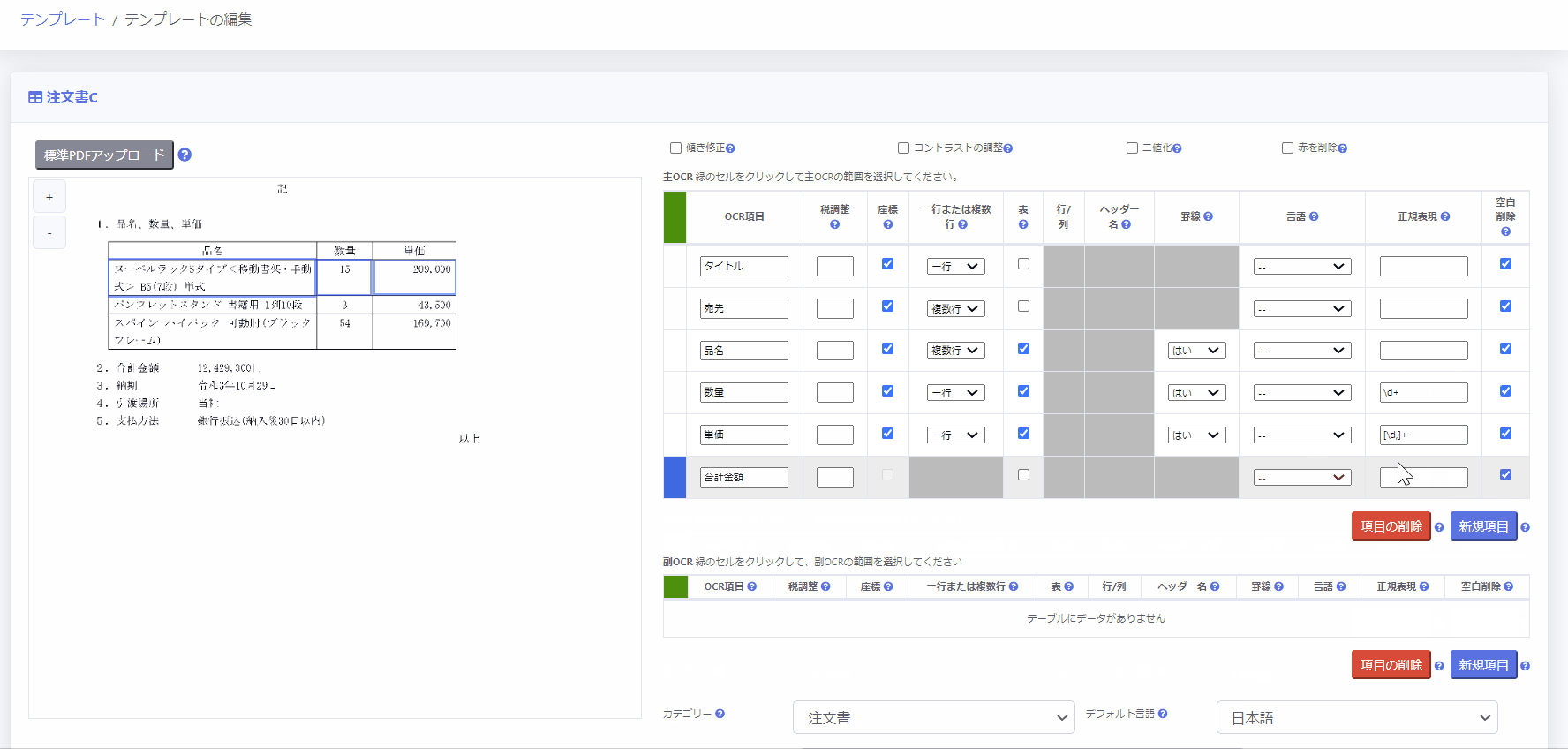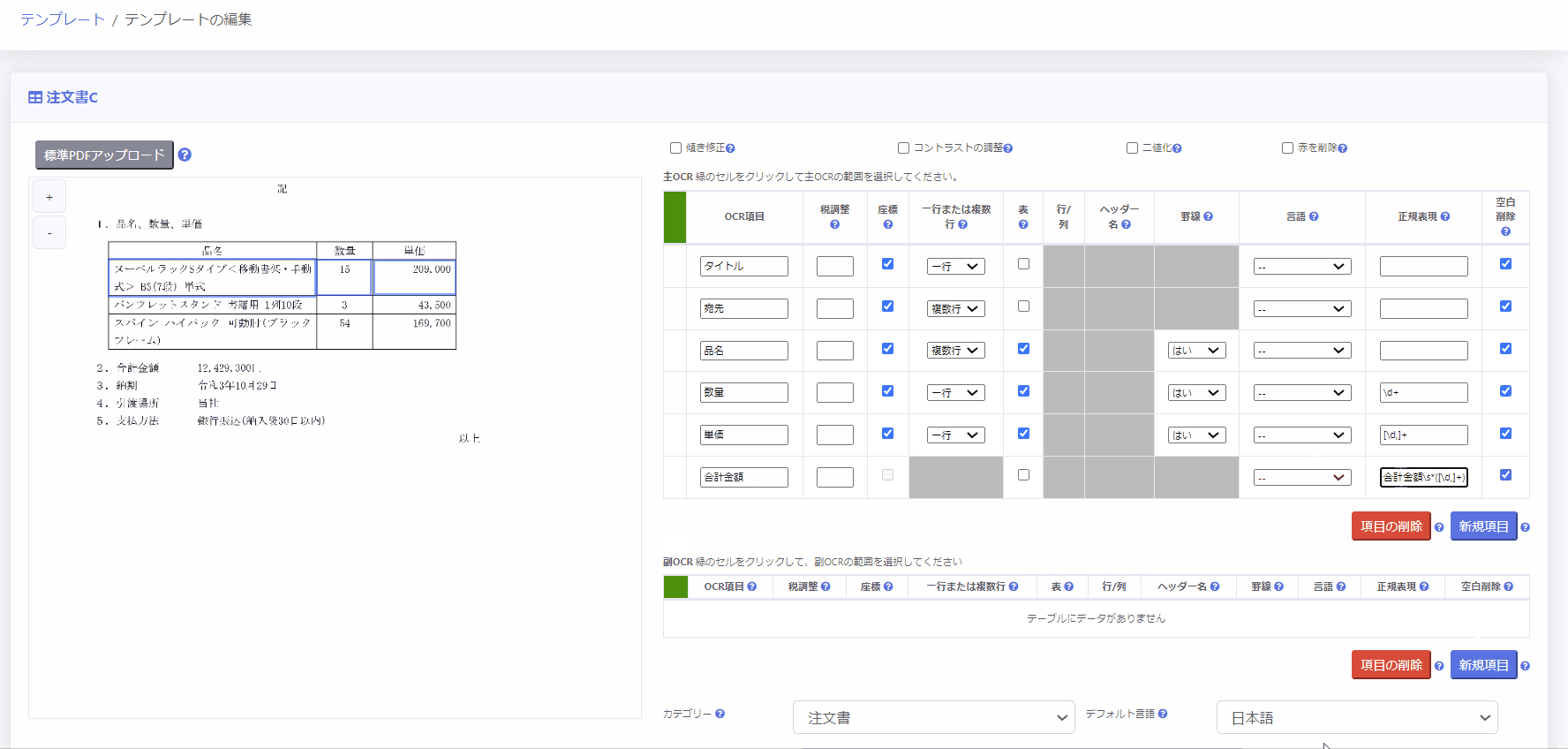
2.OCR領域を設定する
画面右手の「主OCR」「副OCR」の部分でテンプレート設定を行います。
主/副OCR領域を設定すると、OCR対象のPDFに対し、標準PDF上で設定した領域に合わせて回転や切り抜きといった座標補正を行います。
この補正によって紙媒体の証憑をスキャンした際に生じたズレや傾きが修正され、より正確に文字を読み取ることができます。
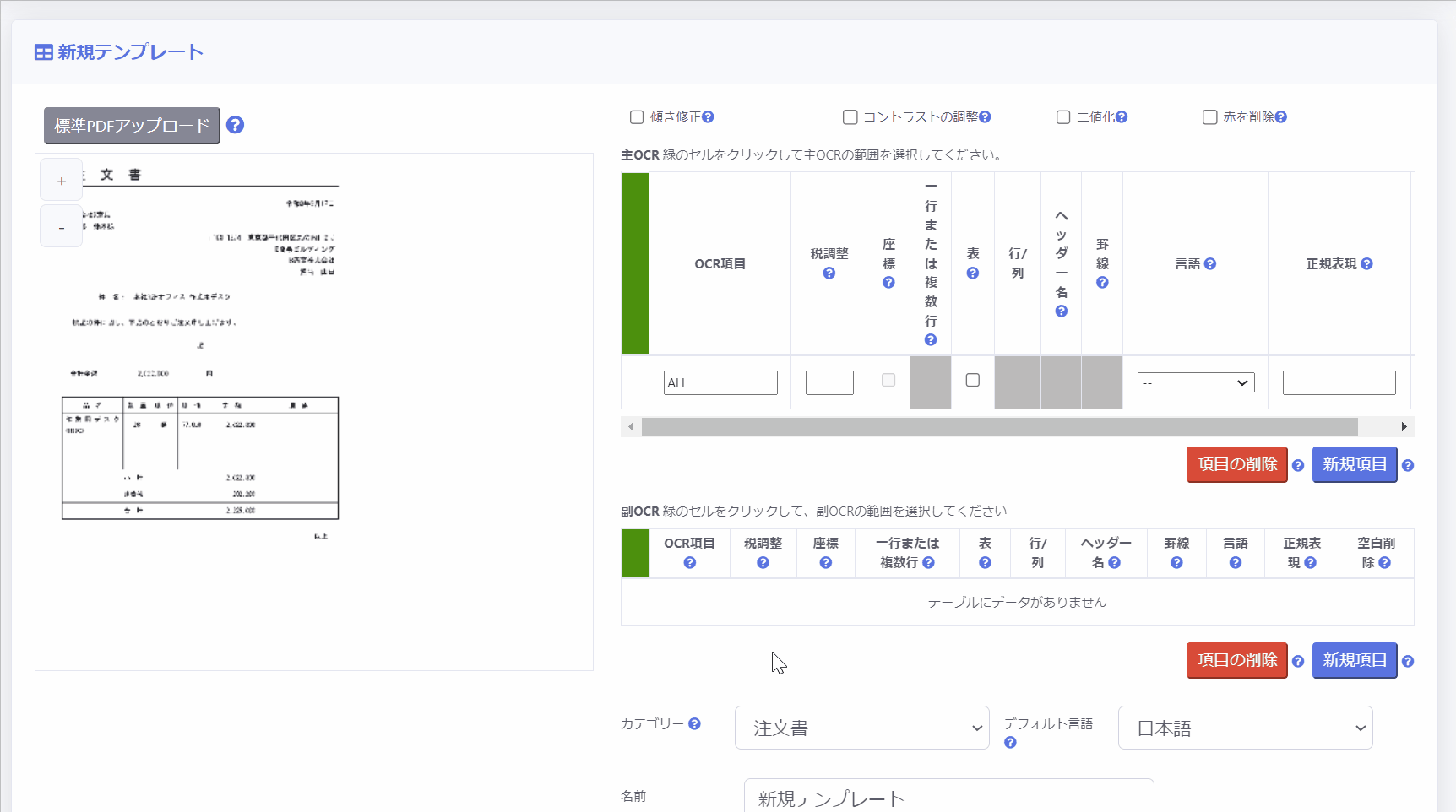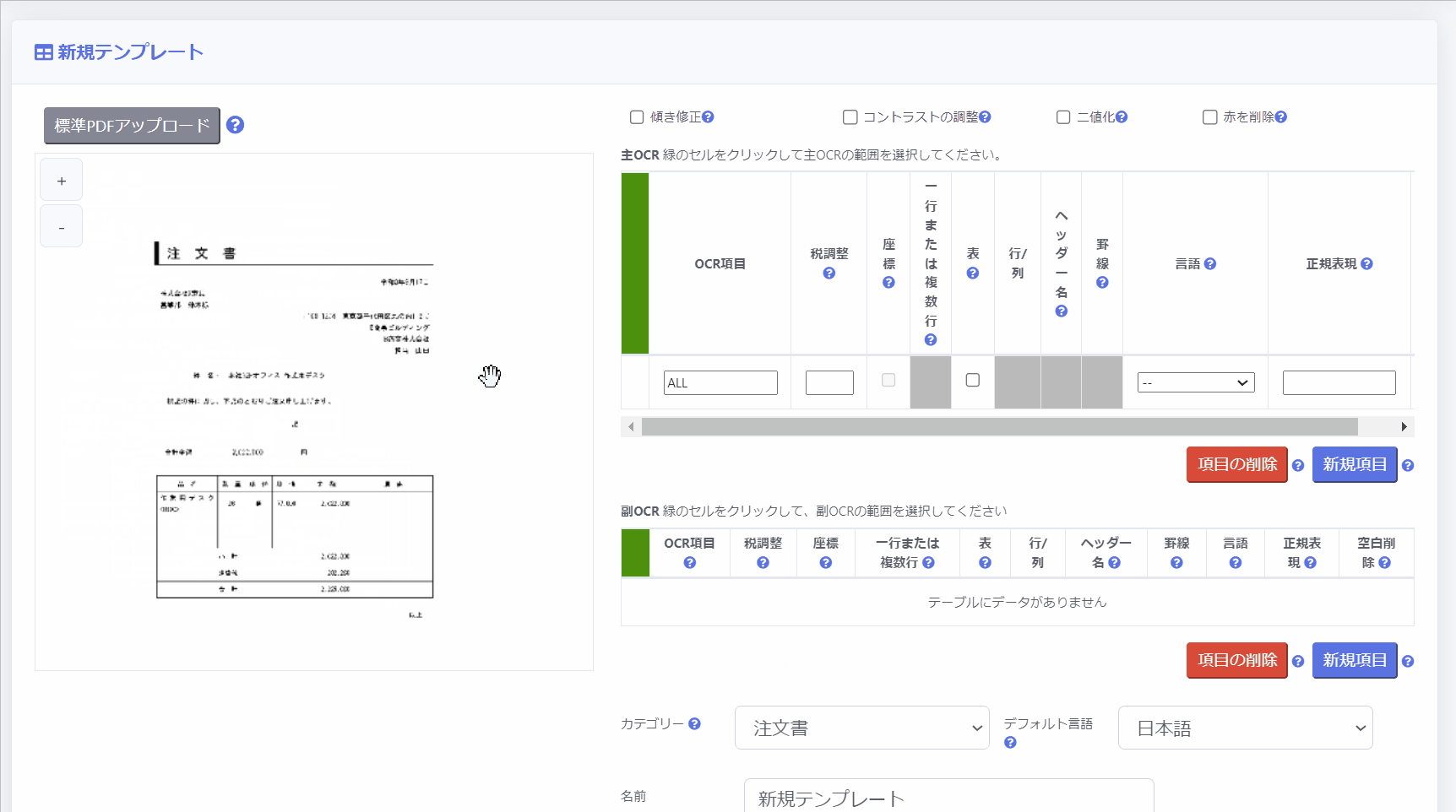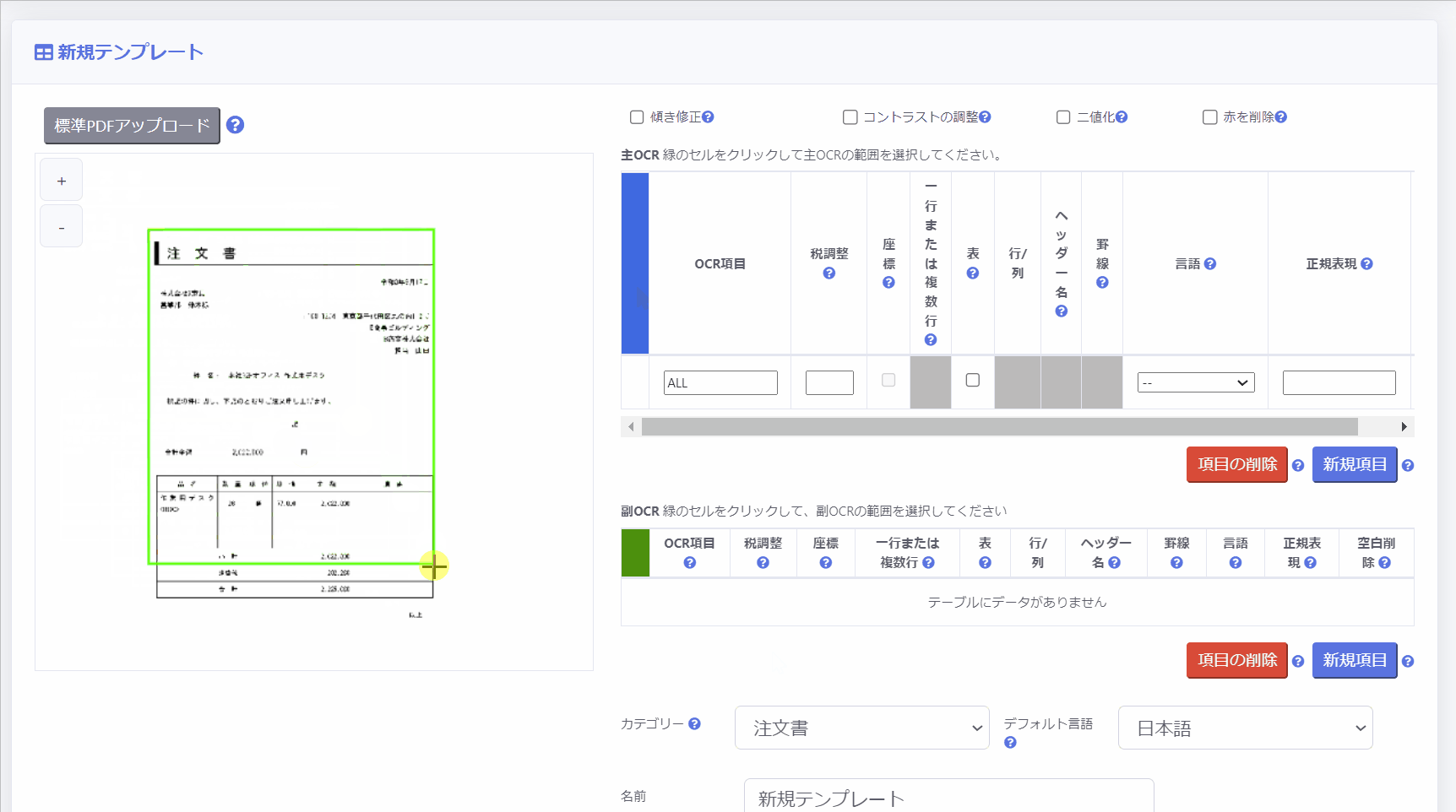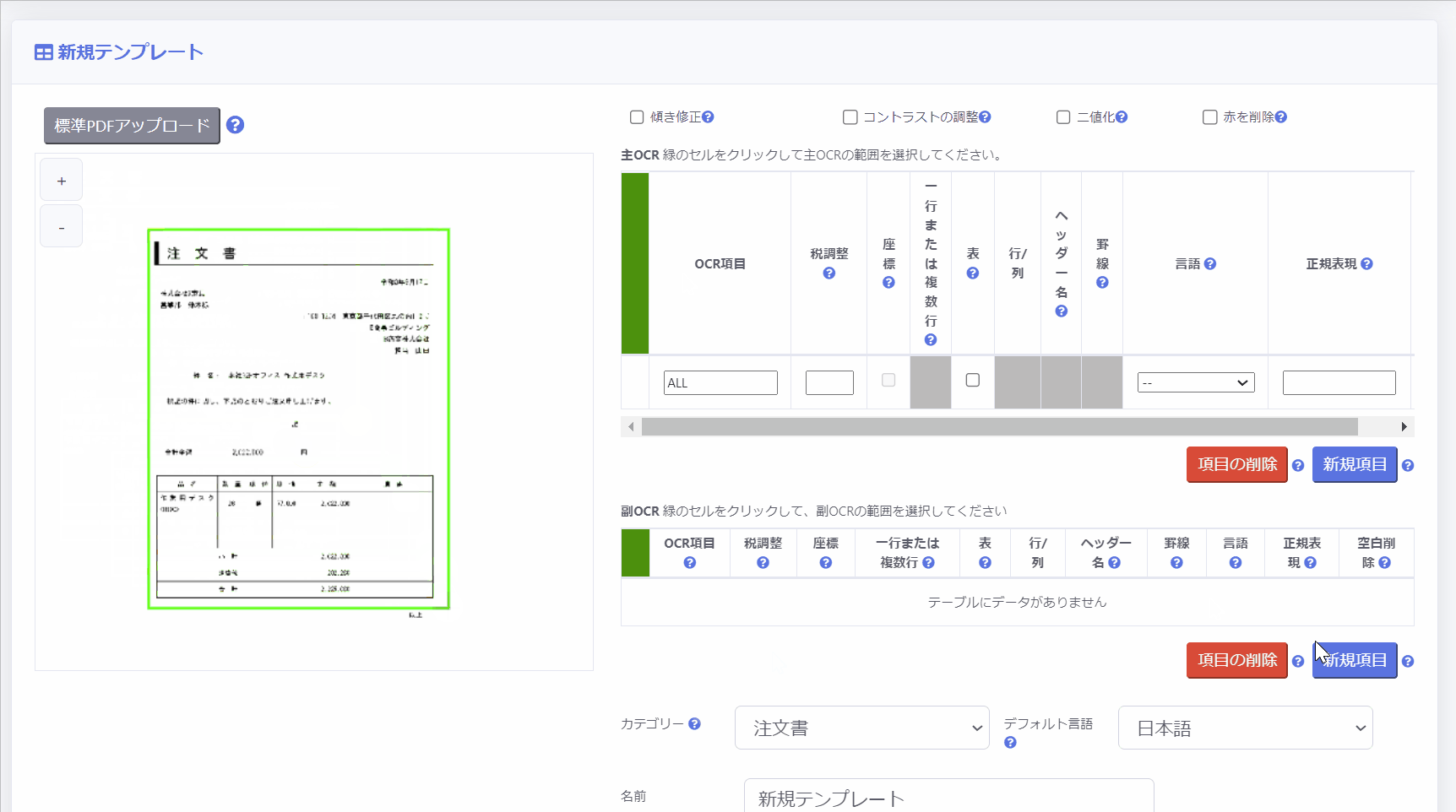
主OCR領域は、PDF全体の範囲を指定するために使用します。
左側のボックスをクリックし、シート全体で範囲を設定します。
※各項目の左側のボックスをクリックし緑色の状態にすると、画面左のページ上でカーソルで範囲を設定することができます。
副OCR領域は、証憑中の承認印・決済印を押すための枠を付けるためのスタンプや表やテーブルなど「証憑の不特定の位置に配置される項目」の範囲を指定するために使用します。
副OCR領域の設定方法は主OCR領域の下のテーブルを使用します。
3.座標指定により設定する
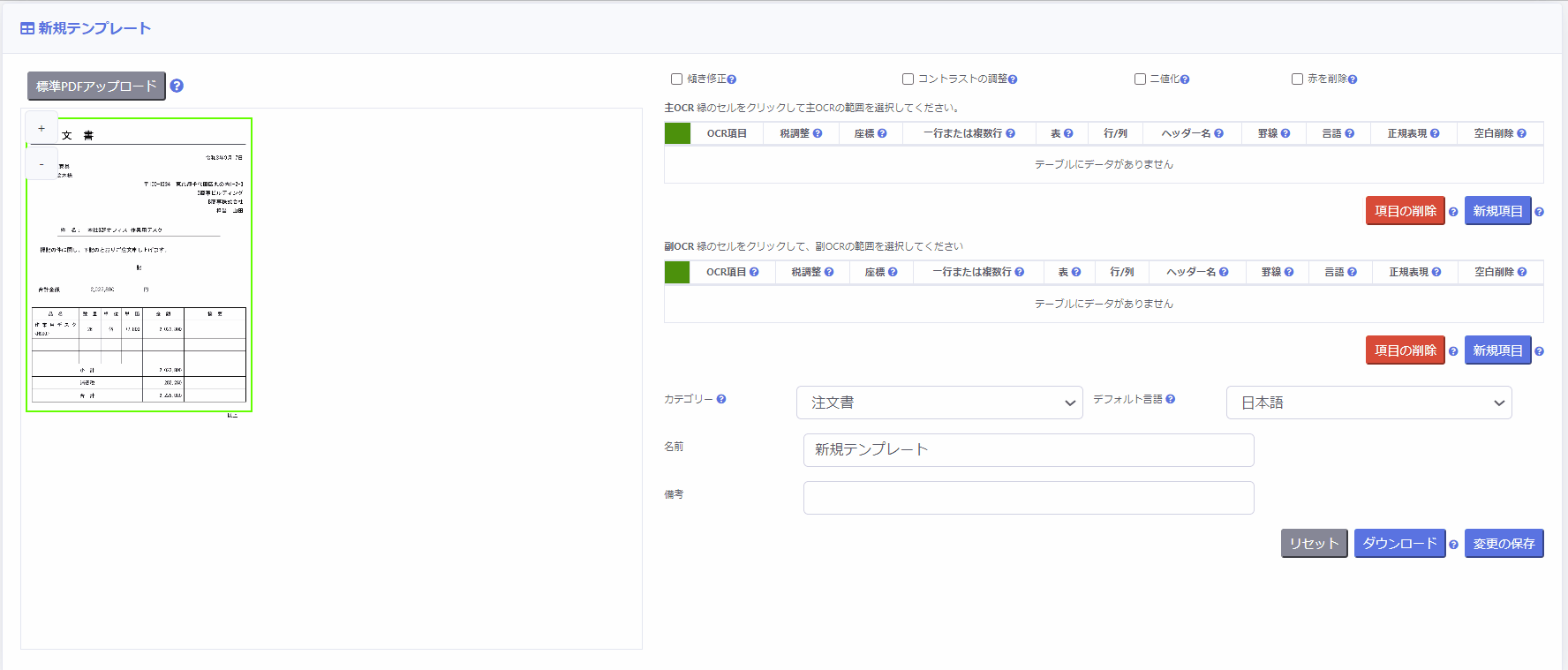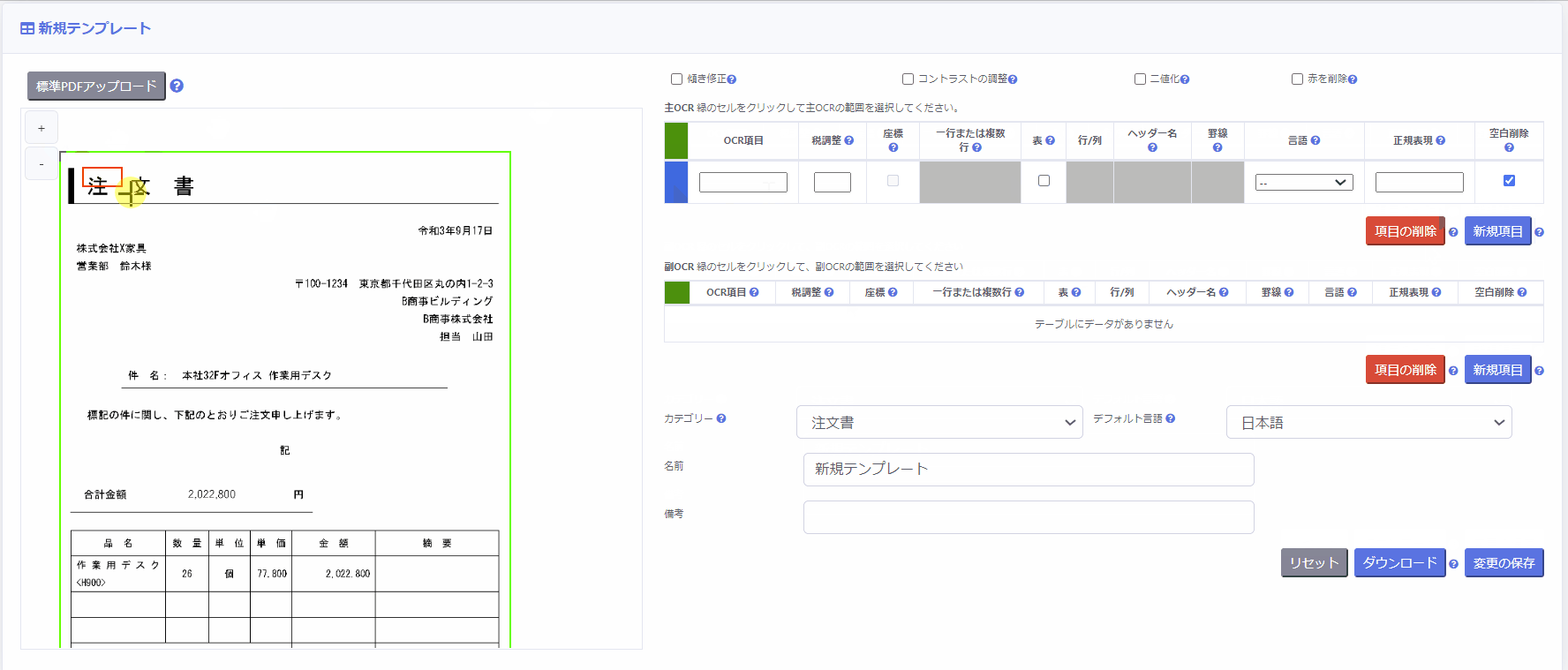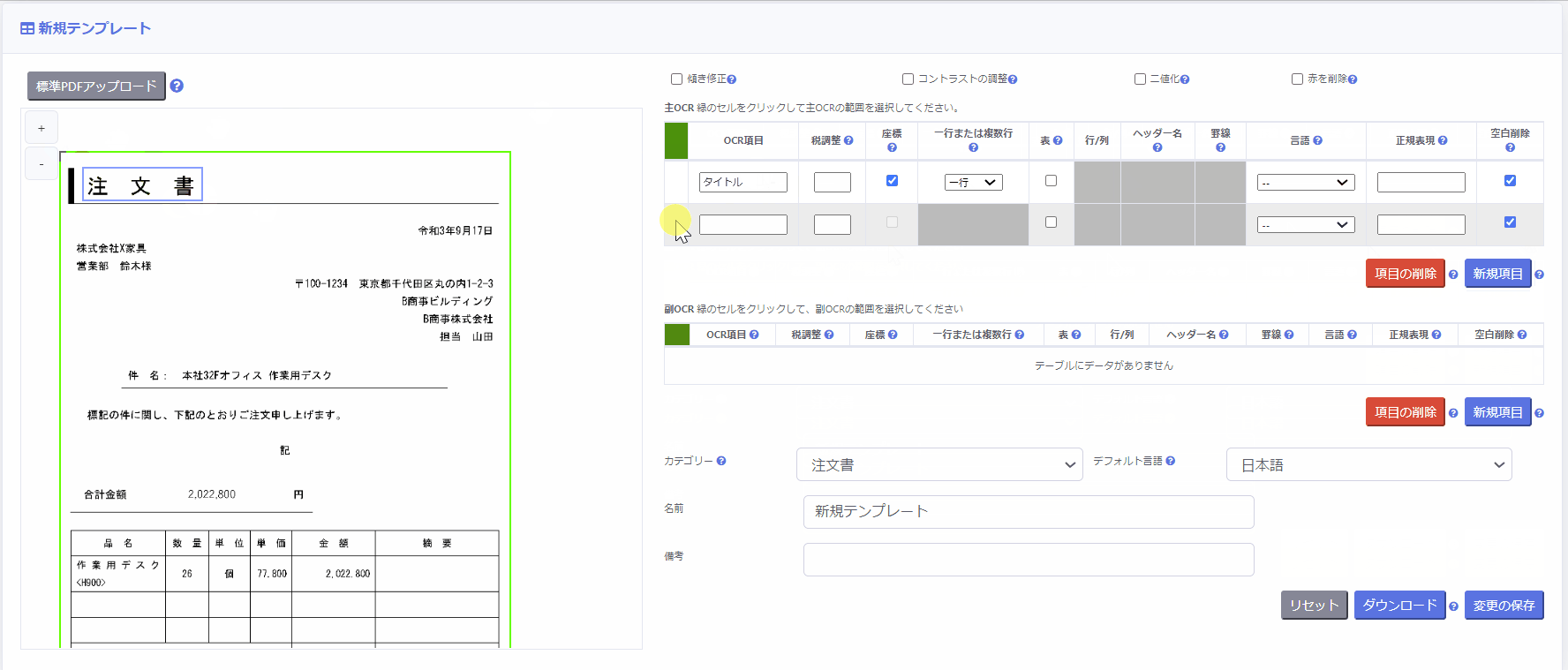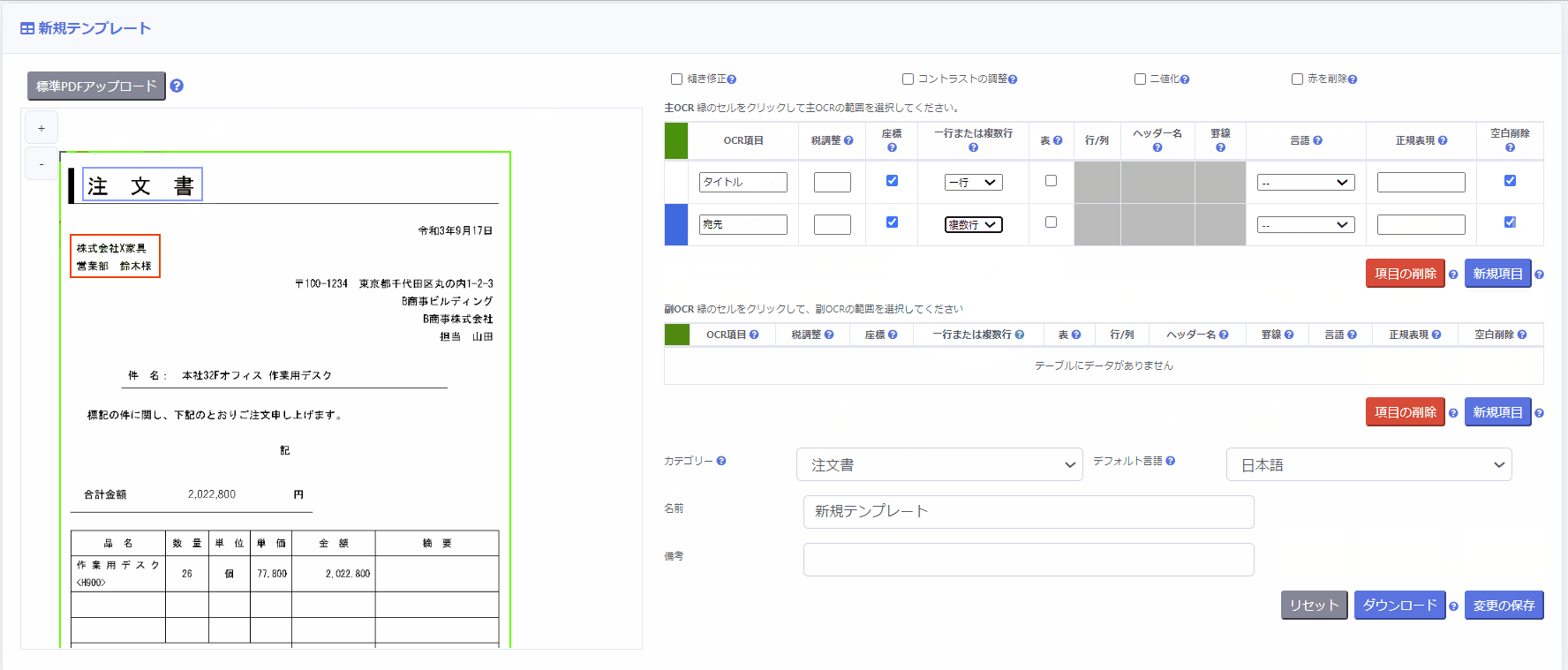
次に、主OCR領域内で、読み取りたい項目を個別に設定していきます。
同様に各項目の左側のボックスをクリックし、ページ上で該当範囲を設定します。
その際、以下の項目を設定します。
※これ以降に登場する設定の場合も、共通して以下の項目をチェックする必要があります。
- OCR項目に名称を入力
例:請求書番号、請求日付、金額、数量、など - [一行または複数行] 列を選択
※対象となるOCR項目の改行を削除して一行とするか、改行を残して複数行とするかを指定します。 - [言語]に対象となるOCR項目の言語を選択
※OCR項目の [言語] が未設定の場合、テンプレート設定画面の下部 [デフォルト言語] が使用されます。 - 空白の削除のチェック有無
OCR結果から余分な空白を削除したい場合にはチェックを入れてください。
※日本語のOCR項目の場合、このチェックボックスにチェックを入れることを推奨します。
4.表により設定する
PDFの表部分を読み取りたい場合、以下の2通りの方法で設定することができます。
また、表部分のOCR結果はリスト形式で出力されます。
1. 表を自動検出する方法 (β版)
- [座標] 列のチェックボックスのチェックを解除
- [表] 列のチェックボックスをチェック
- ヘッダーが表の行として存在する場合は [行/列] 列のラジオボタンから「行」を、列として存在する場合は「列」を選択
- 表から自動的に読み取りたいOCR項目のヘッダー名を [ヘッダー名] 列のプルダウンから選択
2. 表を手動で指定する方法
- [表] 列のチェックボックスをチェック
- 対象となるOCR項目について、表の一行目の範囲を座標選択
OCR実行時、選択した座標から下に向かって一行ずつ自動的に抽出し、OCR結果として読み取ります。 - 表に罫線が存在する場合は [罫線] 列のプルダウンから「はい」を、罫線が存在しない場合は「いいえ」を選択
罫線が存在する場合は、罫線を手掛かりとして読み取ることで正確にセルを認識することができます。
.gif)
5.正規表現により設定する
正規表現とは、文字列を1つのパターン化した文字列で表現する表記法です。
ジーニアルAI for Webでは、正規表現を使用して文字列の検索処理を行うことができます。
ジーニアルAI for Webでは正規表現の中に丸括弧()を指定すると()の中のパターンのみを、丸括弧()を指定しないとパターン全体をOCR結果として抽出します。
例えば、 合計金額\s*([\d,]+) という正規表現パターンを使えば、「合計金額 1,000円」という文字列の中から数値部分の「1,000」を抽出することができます。
使用頻度の高い正規表現
以下が使用頻度の高い正規表現となります。
※OCRが上手く読み取れない場合には、正規表現を使用することで解決することがあります。
お問い合わせフォームより読み取りたい項目をご連絡頂ければ、正規表現をご提案させていただきます。
| 説明 | 正規表現 | 例 |
|---|---|---|
| [数値]のみ抽出する | \d+ | 数量 |
| [数値]と[,]のみを抽出する | [\d,]+ | 単価、合計金額、小計 |
| 合計金額隣の数値のみ抽出する | 合計金額\s*([\d,]+) | 請求金額、合計金額 |
| ○○株式会社御中から会社名のみを抽出する | (/S+)御中 | 宛名 |
| 件名:○○から要件のみ抽出する | 件名:(/S+) | 件名 |
6.テンプレートを保存する
すべてのOCR項目の設定が終了したら、以下の手順でテンプレートを保存します。
- [カテゴリー]を選択
- [デフォルト言語]を選択
※対象となるOCR項目の言語を指定します。 - [名前]にテンプレートの名前を入力
- [変更の保存]をクリック